我将尝试确定在Google Sheets中自动删除某一列中所有单元格中的HTML标记的最佳方法。
单元格数据示例:
<span style="color:#0000FF">test</span>
我希望在每次添加新行时,自动删除所有HTML代码并只保留纯文本。
我不确定是在单元格中使用正则表达式作为公式还是采用某种类型的脚本来实现更好。
我将尝试确定在Google Sheets中自动删除某一列中所有单元格中的HTML标记的最佳方法。
单元格数据示例:
<span style="color:#0000FF">test</span>
我希望在每次添加新行时,自动删除所有HTML代码并只保留纯文本。
我不确定是在单元格中使用正则表达式作为公式还是采用某种类型的脚本来实现更好。
=REGEXREPLACE(A1,"</?\S+[^<>]*>","")
这个公式也可以转换为ArrayFormula:
=ARRAYFORMULA(REGEXREPLACE(offset(A1,,,COUNTA(A:A)),"</?\S+[^<>]*>",""))
这个公式会自动填充。COUNTA(A:A) 是列[A]中包含数据的行数。
</?\S+[^<>]*>
替换为:<空字符串>
搜索:特定范围 = '<SHEET_NAME>'!<COLUMN>:<COLUMN> (例如'Sheet1 的副本'!A:A)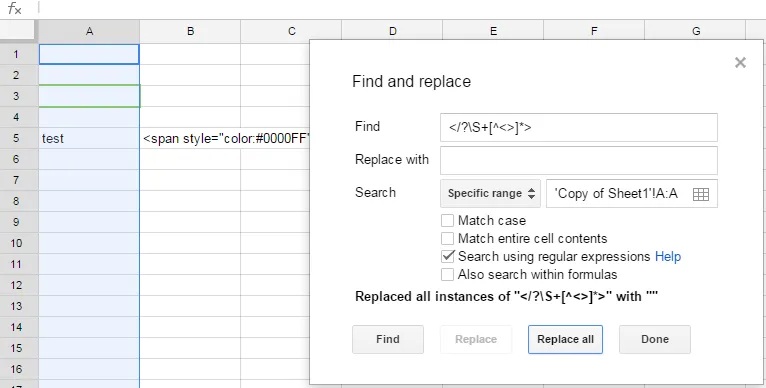
我喜欢Max Makhrov的方法,但稍微简单一点的正则表达式如下:
"<[^<>]+>"
=REGEXREPLACE(A1,"<[^<>]+>","")
如果你回顾一下Max的作品,他包括的其他元素有:
/?
\S+
"\S"表示任何非空白字符。"+"表示出现一次或多次。因此,斜杠后面跟着一些可见字符。
然后他有"[^<>]*"——任何非尖括号字符零次或多次,最终找到那个闭合括号。因此,在我们最后一组字符停止后(即,我们遇到空格),然后开始搜索那个闭合括号。
但是斜杠、非空白字符——我们可以直接让"[^<>]"从一开始就为我们完成所有工作。我们可能会使用"+"而不是"*",以确保在标记中至少找到一个字符。(如果您想去除“空”标记,可以将其设为"*"...我不确定什么时候会出现这些情况。)
因此,我的版本在某种意义上更加“愚蠢”。它只是说,让我们不用管是否有斜杠、空格或其他东西,而是只取得两个尖括号之间的任何内容。
您可能会注意到,这修复了Max原始答案中的一个微妙错误,即如果条目和标记中没有任何空格,它将删除整个字段。"\S+"是“贪婪”的。因此,如果您遇到像这样的东西:
"<b>test1</b><div>test2</div>
"</?\S+?[^<>]*>"
如果你使用我更简单的版本,即 <[^<>]+>,那么它贪婪匹配会没问题,因为只要它找到下一个尖括号,就会立即停止,而不需要考虑空格。
所以,要么:
=REGEXREPLACE(A1,"<[^<>]+>","")
=ARRAYFORMULA(REGEXREPLACE(offset(A1,,,COUNTA(A:A)),"<[^<>]+>",""))
祝你好运!
<b>我</b>是老师。<div>(<b>我</b>是老师。)</div>仍在尝试调试... - Brownbat"<[^<>]+>"对我的情况很有效。打开括号,一些不是尖括号的字符,然后关闭括号。 - Brownbat