有人知道Git在文件数量和文件大小方面的限制吗?
Git 中文件的限制是什么(数量和大小)?
192
- Alexandre Rademaker
1
1在Windows上,由于一个错误(https://github.com/git-for-windows/git/issues/1063),最大文件大小为4 GB(截至2020年7月)。 - cowlinator
11个回答
179
这条来自林纳斯本人的消息可以帮助你解决一些其他限制
请看我其他答案中的更多内容:Git的限制在于每个仓库必须代表一个“一致的文件集”,即整个系统本身(你不能标记“仓库的一部分”)。[...] CVS,即它实际上几乎完全是面向“一次一个文件”的模型。
这很好,因为您可以有数百万个文件,然后仅检查其中的一些文件-您甚至不会看到其他999,995个文件的影响。
Git从根本上来说永远不会真正地只关注部分内容。即使您将事情限制在某种程度上(即仅检出一部分,或者历史记录仅返回一点),Git最终仍然始终关心整个内容,并携带着这些知识。
因此,如果您强制Git将所有内容视为一个巨大的存储库,则Git的扩展性非常差。我认为那部分真的无法修复,尽管我们可能可以对其进行改进。
是的,然后还有“大文件”问题。我真的不知道该怎么处理大文件。我知道我们做得不好。
如果你的系统由自治但相互依赖的部分组成,你必须使用子模块。
正如Talljoe的答案所示,限制可能是一个系统级别的(大量文件),但如果你了解Git的本质(关于数据一致性由其SHA-1密钥表示),你会意识到真正的“限制”是用法的:即,你不应该尝试将所有东西都存储在Git仓库中,除非你准备好始终获取或标记所有内容。对于一些大型项目来说,这是没有意义的。
如果想更深入地了解git限制,请参考 "git with large files" (提到了git-lfs: 一种将大文件存储在git仓库外的解决方案。GitHub,2015年4月)
影响git仓库的三个问题:
- 大文件(xdelta for packfile仅在内存中,对于大文件并不理想)
- 大量文件,这意味着每个blob一个文件,git gc生成一个packfile会很慢。
- 大packfiles,用于检索数据的packfile索引效率低下。
一篇较新的帖子(2015年2月)说明了Git仓库的限制因素:
从中央服务器克隆几个同时的副本是否也会减慢其他用户的并发操作?
在克隆时服务器没有锁,因此理论上克隆不会影响其他操作。但是克隆可能会使用大量内存(除非您打开可达性位图功能,这样可以节省大量 CPU 使用率)。
'
git pull'会很慢吗?如果我们排除服务器端,那么你的树大小是主要因素,但你的 25k 个文件应该没问题(Linux 有 48k 个文件)。
'
git push'呢?这个不受您的仓库历史记录有多深或者树有多宽的影响,因此应该很快。
啊,引用的第三个参考文献中可能会影响
git-push和git-pull的引用数量。
我认为 Stefan 在这方面更加专业。'
git commit'呢?(在参考文献3中列为慢速操作。) 'git status'呢?(虽然我没有看到它在参考文献3中。) (还有git-add)同样,取决于您的树大小。在您的仓库大小下,我认为您不需要担心。
一些操作可能看起来不是每天都使用的,但如果它们被 GitLab/Stash/GitHub 等 Web 前端频繁调用,则可能成为瓶颈。(例如,'
git branch --contains' 在大量分支时似乎受到严重影响。)当文件被频繁修改时,
git-blame可能会很慢。
- VonC
5
4@Thr4wn: 请参考这个链接https://dev59.com/mXI-5IYBdhLWcg3wMFMf#1979194,了解GitPro子模块页面的更多信息。如果需要一个更简短的版本,请看这个链接:https://dev59.com/oEvSa4cB1Zd3GeqPdVPy#2065749 - VonC
1Git子模块文档的更新链接为:http://git-scm.com/book/en/Git-Tools-Submodules。 - JHowIX
我真的很好奇,在Linux上有这么多的SQLite和许多数据库替代品可用,为什么他们不能简单地使用易于备份、复制和扩展的数据库呢? - Akash Kava
如果你强制让git将所有内容视为一个“巨大”的存储库,它的扩展性会非常糟糕。这句话对于单体仓库的可扩展性有何启示? - ephemer
1@ephemer,它的意思是... 那段引用来自十年前。从那时起,微软已经拥有了自己的 monorepo(https://devblogs.microsoft.com/bharry/the-largest-git-repo-on-the-planet/: 300GB+),并且在2019年仍在不断改进:https://dev59.com/JZnga4cB1Zd3GeqPfvLJ#57129687。 - VonC
40
没有真正的限制 - 一切都使用160位的名称来命名。文件的大小必须能够用64位数字表示,因此也没有真正的限制。
但是有一个实际的限制。我有一个存储了880,000个以上文件、大约8GB的存储库,git gc需要一段时间。工作树相当大,因此检查整个工作目录的操作需要相当长的时间。不过这个存储库只用于数据存储,所以只是一堆自动化工具在处理它。从存储库中拉取更改比使用rsync同步相同的数据要快得多。
%find . -type f | wc -l
791887
%time git add .
git add . 6.48s user 13.53s system 55% cpu 36.121 total
%time git status
# On branch master
nothing to commit (working directory clean)
git status 0.00s user 0.01s system 0% cpu 47.169 total
%du -sh .
29G .
%cd .git
%du -sh .
7.9G .
- Talljoe
3
3虽然上面有一个关于理论限制的“更正确”的答案,但是我认为这个答案更有帮助,因为它允许将自己的情况与你的情况进行比较。谢谢。 - Bananeweizen
1非常有趣。工作副本怎么可能比
.git 目录还要大呢?我天真地以为 .git 包含了工作目录的副本和历史记录,所以它一定更大。谁能指导我了解这些大小是如何相关的资源? - bluenote102@bluenote10
.git 目录中的内容是经过压缩的。因此,相对较少提交的存储库可能具有比未压缩的工作目录更小的压缩历史记录。我的经验表明,在实践中,对于 C++ 代码,整个历史记录通常与工作目录的大小大致相同。 - prapin28
如果您添加的文件过大(在我的情况下,GB级别,Cygwin、XP、3 GB RAM),就会出现这种情况。
致命错误:内存不足,malloc失败
更多细节请查看此处
更新于3/2/11:在Windows 7 x64上使用Tortoise Git时也遇到了类似问题。大量内存被占用,系统响应非常缓慢。
- Brian Carlton
17
- CharlesB
1
2+1 有趣。这与我关于git限制的回答相呼应,详细说明了大文件/文件数量/包文件的限制。 - VonC
2
这取决于您的意思是什么。如果您有很多大文件,它可能会变得非常缓慢。如果您有很多文件,扫描速度也会变慢。
但是,模型并没有固有的限制。您当然可以使用不当,感到痛苦。
- Dustin
2
截至2023年,我的经验法则是尽量保持你的仓库文件总数小于524288个(包括文件和目录),可能还有几百GB的空间...但是我刚刚处理了2.1M个文件,占用了107GB的空间。
这个524288的数字似乎是Linux能够同时跟踪更改的最大inode数(通过“inode watches”),我认为这就是
当您收到关于没有足够`inotify`监视的警告时,这是因为您存储库中的文件数量超过了当前的`inotify`限制。增加限制允许`inotify`(以及Git)跟踪更多的文件。然而,这并不意味着Git在超过此限制后将无法工作:如果达到限制,`git status`或`git add -A`不会“错过”更改。相反,这些操作可能会变得较慢,因为Git需要手动检查更改,而不是从inotify机制获取更新。
所以,您可以超过524288个文件(我的存储库包含2.1M个文件),但速度会变慢。
我的实验:
我刚刚添加了2095789个(约2.1M)文件,总共约107GB,到一个全新的存储库中。这些数据基本上只是一个300MB的代码和构建数据块,在多年间被重复数百次,每个新文件夹都是前一个文件夹的略有变化的修订版。
Git做到了,但它并不喜欢这样。我使用的是一台非常高端的笔记本电脑(20个核心,快速,Dell Precision 5570笔记本电脑,64 GB内存,高速真实世界的3500 MB/sec m.2 2 TB固态硬盘),运行着Linux Ubuntu 22.04.2,并且这是我的结果:
这个524288的数字似乎是Linux能够同时跟踪更改的最大inode数(通过“inode watches”),我认为这就是
git status如何快速找到更改文件的方式--通过inode通知或其他方式。更新:来自@VonC, below的信息:当您收到关于没有足够`inotify`监视的警告时,这是因为您存储库中的文件数量超过了当前的`inotify`限制。增加限制允许`inotify`(以及Git)跟踪更多的文件。然而,这并不意味着Git在超过此限制后将无法工作:如果达到限制,`git status`或`git add -A`不会“错过”更改。相反,这些操作可能会变得较慢,因为Git需要手动检查更改,而不是从inotify机制获取更新。
所以,您可以超过524288个文件(我的存储库包含2.1M个文件),但速度会变慢。
我的实验:
我刚刚添加了2095789个(约2.1M)文件,总共约107GB,到一个全新的存储库中。这些数据基本上只是一个300MB的代码和构建数据块,在多年间被重复数百次,每个新文件夹都是前一个文件夹的略有变化的修订版。
Git做到了,但它并不喜欢这样。我使用的是一台非常高端的笔记本电脑(20个核心,快速,Dell Precision 5570笔记本电脑,64 GB内存,高速真实世界的3500 MB/sec m.2 2 TB固态硬盘),运行着Linux Ubuntu 22.04.2,并且这是我的结果:
git --version显示git version 2.34.1。git init瞬间完成。time git add -A花了17分37.621秒。time git commit大约花了11分钟,因为它显然需要运行git gc来打包文件。我建议使用
time git commit -m "Add all files",这样就不会让你的文本编辑器打开一个有2.1M行的文件。我已经按照这里的指示将Sublime Text设置为我的git编辑器,并且它处理得还可以,但是打开文件需要几秒钟的时间,而且没有正常情况下的语法高亮。当我的提交编辑器仍然打开并且我正在输入提交消息时,我收到了这个GUI弹窗:
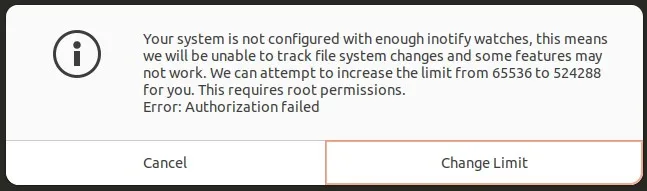
文本内容:
您的系统未配置足够的inotify监视器,这意味着我们将无法跟踪文件系统的更改,某些功能可能无法正常工作。我们可以尝试将限制从65536增加到524288。这需要root权限。
错误:授权失败所以,我点击了“更改限制”并输入了我的root密码。
这似乎表明,如果您的存储库有超过524288(约500k)个文件和文件夹,那么git无法保证使用
git status检测到更改的文件,对吗?在我的提交编辑器关闭后,这是我的计算机在提交和打包数据时的情况:
请注意,我的基线RAM使用量大约为17 GB,所以我猜只有大约10 GB的RAM使用量来自
git gc。实际上,“眼测”下面的内存图显示,我的RAM使用量从提交之前的大约25%上升到提交期间的大约53%,总使用量为53-23 = 28% x 67.1 GB = 18.79 GB左右的RAM使用量。这是有道理的,因为事后看,我发现我的主要pack文件大小为10.2 GB,位置在这里:
.git/objects/pack/pack-0eef596af0bd00e16a9ba77058e574c23280e28f.pack。因此,从逻辑上来说,加载该文件到RAM并处理它进行打包至少需要这么多的内存。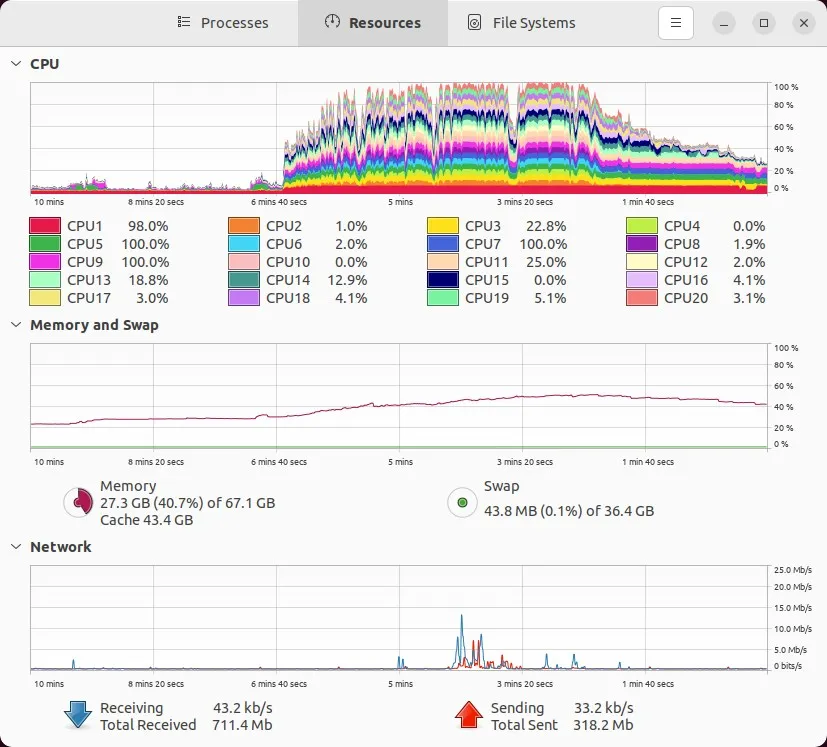
这是git在屏幕上打印的内容:
$ time git commit 正在后台自动打包存储库以获得最佳性能。 有关手动维护,请参阅“git help gc”。完成需要大约11分钟。
time git status现在是干净的,但是需要大约2~3秒钟。有时会打印出正常的消息,例如:$ time git status 在分支main上 没有要提交的内容,工作树干净 <p>这结束了我在git中进行的真实数据测试。我建议您坚持使用< 500k个文件。尺寸方面,我不知道。也许你可以用50 GB、2 TB或10 TB来应对,只要你的文件数量接近500k个文件或更少。</p> <h2>进一步操作:</h2> <h3>1. 通过我的11 GB <code>.git</code>目录给某人我的107 GB存储库</h3> <p>现在,git已将我2.1M个文件的107 GB压缩成一个11 GB的<code>.git</code>目录,我可以轻松地重新创建或共享这个<code>.git</code>目录给我的同事,以便将整个存储库交给他们!不要复制整个123 GB的存储库目录。相反,如果您的存储库名为<code>my_repo</code>,只需在外部驱动器上创建一个空的<code>my_repo</code>目录,将<code>.git</code>目录复制到其中,然后将其交给同事。他们将其复制到他们的计算机上,然后像这样重新实例化存储库中的整个工作树:</p> <pre class="lang-bash prettyprint-override"><code>cd path/to/my_repo # Unpack the whole working tree from the compressed .git dir. # - WARNING: this permanently erases any changes not committed, so you better # not have any uncommitted changes lying around when using `--hard`! time git reset --hard
对我来说,在这台高端电脑上,time git reset --hard解压命令花费了7分32秒,而git status现在是干净的。
如果.git目录被压缩在一个.tar.xz文件中,名为my_repo.tar.xz,那么指令可能会变成这样: 如何从只包含11 GB.git目录的my_repo.tar.xz文件中恢复整个107 GB的my_repo仓库:# Extract the archive (which just contains a .git dir) mkdir -p my_repo time tar -xf my_repo.tar.xz --directory my_repo # In a **separate** terminal, watch the extraction progress by watching the # output folder grow up to ~11 GB with: watch -n 1 'du -sh my_repo' # Now, have git unpack the entire repo cd my_repo time git status | wc -l # Takes ~4 seconds on a high-end machine, and shows # that there are 1926587 files to recover. time git reset --hard # Will unpack the entire repo from the .git dir!; # takes about 8 minutes on a high-end machine.2. 使用
meld比较复制文件夹修订版本之间的变化按照以下步骤进行操作:
meld path/to/code_dir_rev1 path/to/code_dir_rev2
Meld打开一个文件夹比较视图,就像你在文件浏览器中一样。更改的文件夹和文件将被着色。点击进入文件夹,然后点击更改的文件,以查看它们在并排比较视图中的变化。Meld会在新标签页中打开此视图。完成后关闭标签页,返回文件夹视图。找到另一个更改的文件,然后重复上述步骤。这使我能够快速比较这些更改的文件夹版本,而无需手动将它们首先输入到线性git历史记录中,就像它们本应该在第一次出现时那样。
另请参阅:
我的回答:如何使用多个进程递归地在所需的目录或路径上运行dos2unix(或任何其他命令)。
Git是否在文件之间进行了去重? 我的回答:
Brian Harry,来自微软,在“地球上最大的Git存储库”上 - 微软显然有一个巨大的300 GB单一存储库,其中包含3.5M个文件,几乎包含他们所有的代码。(我真不想成为远程工作者并尝试拉取那个...)
@VonC关于提交图链和Git的快速性。
- Gabriel Staples
5
1好的分析。点赞。正如我在下面提到的,自2017年起,微软一直在管理一个更大的代码库,并通过提交图表向Git做出了贡献,使您能够实例化大型Git库。 - VonC
谢谢,@VonC。我对inode的事情理解正确吗?当Linux只能追踪524,288个inode时,对于我拥有2.1百万个文件的仓库意味着什么?
git status和git add -A会不会有时候错过我的更改? - Gabriel Staples1当您收到关于没有足够
inotify监视器的警告时,这是因为您的存储库中的文件数量超过了当前的inotify限制。增加限制可以让inotify(以及Git)跟踪更多的文件。然而,这并不意味着Git在超过此限制后将无法工作:如果达到限制,git status或git add -A不会“错过”更改。相反,这些操作可能会变得较慢,因为Git需要手动检查更改,而不是从inotify机制获取更新。 - VonC@VonC,谢谢!很有道理。我把你的引用添加到了我的回答顶部。我还加了一个
'status -uno'的信息,这是我现在有时候在git status中看到的(在我的回答中搜索一下)。你以前见过这个吗?这是因为我超出了inotify watches的限制吗? - Gabriel Staples1
我发现在存储大量文件(350k+)时使用版本库。是的,存储。哈哈。
$ time git add .
git add . 333.67s user 244.26s system 14% cpu 1:06:48.63 total
以下是来自Bitbucket 文档的摘录,非常有趣。
当您使用DVCS存储库克隆、推送时,您正在使用整个存储库及其所有历史记录。实际上,一旦您的存储库大于500MB,您可能会开始遇到问题。... 94%的Bitbucket客户端拥有小于500MB的存储库。Linux内核和Android都小于900MB。
该页面上推荐的解决方案是将您的项目拆分成较小的块。
- Kasisnu
1
我猜这已经相当过时了。现在,您链接的网站上似乎没有关于Android(也没有关于Linux)存储库的任何信息。但是我想知道即使那时候是否不准确?例如,请比较此答案。也许他们指的是其他东西? - jjj
1
我认为尽量避免将大文件提交到代码库中是一个好的做法(例如,数据库转储最好放在其他地方),但如果考虑到内核在其代码库中的大小,那么你可以预期与任何比它更小且不太复杂的东西一起轻松工作。
- Kzqai
1
我有大量的数据存储在我的仓库中,这些数据以单独的JSON片段形式存储。大约有75,000个文件分布在几个目录下,并且不会对性能造成太大影响。
第一次检查它们时,显然会有点慢。
- funwhilelost
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接