在处理数据库时,如何使用关系代数找到最大值(MAX)?
8个回答
89
假设你有一个只包含单个属性'a'的关系A(将更复杂的关系简化为这个是关系代数中的一项简单任务,我相信你已经了解到这一步骤),现在你想要找到A中的最大值。
其中一种方法是对A自身进行叉乘,确保重命名'a'以使新的关系具有不同名称的属性。例如:
(将'a'重命名为'a1') X (将'a'重命名为'a2')
然后选择'a1' < 'a2',得到的关系将包含除最大值以外的所有值。要获取最大值,只需找到原始关系的差异即可:
(A x A) - (select 'a1' < 'a2') ((rename 'a' as 'a1')(A) x (rename 'a' as 'a2')(A))
按照 Tobi Lehman 在下面的评论中建议的,使用 project 运算符将其缩减为单列。
用关系代数符号表示如下(如果我没记错的话)。请注意,最后的重命名(即 ρ)只是为了得到一个与原始关系中相同名称的属性:
ρa/a1(πa1((A x A) - σa1 < a2 (ρa1/a(A) x ρa2/a(A))))
- Dan
5
7只是一个小问题,但是差集表达式A-(...)应该是(A×A - (...)),因为右边的集合充满了对。然后,在减去所有对之后,使用投影运算符来提取它。 - tlehman
1这个答案只有部分正确。首先,我不认为
A x A 是被很好定义的,因为 A 和 A 有共同的属性(显然因为它们有相同的模式),而一个关系不能有重复的属性。你自己也注意到了这一点,我猜你只是忘记在左边的笛卡尔积上执行与右边相同的重命名。 - user_1此外,您需要对
A与自身的笛卡尔积取差集,并且还要从A与自身的笛卡尔积中获取所有元组,其中a1 < a2。这将导致一个关系,其中a1 >= a2。最后,您需要投影到a1并将a1重命名为a,这样您就得到了与开始时相同的关系实例A。我不知道为什么这个答案没有被纠正就获得了这么多赞,也许我的推理有问题?@idipous答案的最后一部分是正确回答该问题的方法。 - user_2@gblomqvist 是的,你说得对,我查看了编辑历史,最初只有
A - ... 和一条评论说你仍然需要进行投影,但后来我根据tlehman上面的评论进行了更改。idipous的答案更完整。 - Dan这是错误的,因为在从
A x A 中减去 a2 之前你没有将其投影出来。 - palapapa45
今天我自己试图解决这个问题,只是提供我的两分意见。
假设我们有A = 1,2,3
如果您使用
A x A - (select 'a1' < 'a2') ((rename 'a' as 'a1')(A) x (rename 'a' as 'a2')(A))
您将不会得到单一的最大值,而是两列值,例如 1|1、2|1、3|2、3|1、3|2、3|3
获取仅为 3 的方法是:
project(a)A - project(a1)((select 'a1' < 'a2') ((rename 'a' as 'a1')(A) x (rename 'a' as 'a2')(A)))
至少在类似情况下,这就是我必须要做的事情。
希望能对某人有所帮助。
- idipous
32
假设我们有一个带属性A和值1、2、3的关系
A
1
2
3
现在,项目A的价值被重新命名为A1。
A1
1
2
3
再次将A项目的值重命名为A2。
A2
1
2
3
使用\join_{A2<A1}将其连接,其中A2<A1,即可得到 - 输出模式:
(A2 integer, A1 integer)
A2<A1
1|2
1|3
2|3
由于我们这样加入(a2<a1),因此始终 A2 值会小于 A1。
现在,项目 A2 的输出如下所示:
A2
1
2
现在与原始属性不同
A diff A2
A
1
2
3
diff
A2
1
2
输出的最大值为3
- bhv
19
我已经忘记了大部分关系代数的语法。只使用SELECT、PROJECT、MINUS和RENAME的查询将是:
SELECT v1.number
FROM values v1
MINUS
SELECT v1.number
FROM values v1 JOIN values v2 ON v2.number > v1.number
希望您能进行翻译!
- Martin Smith
5
我知道这已经过时了,但这里有一份手写的公式可能会很有用!
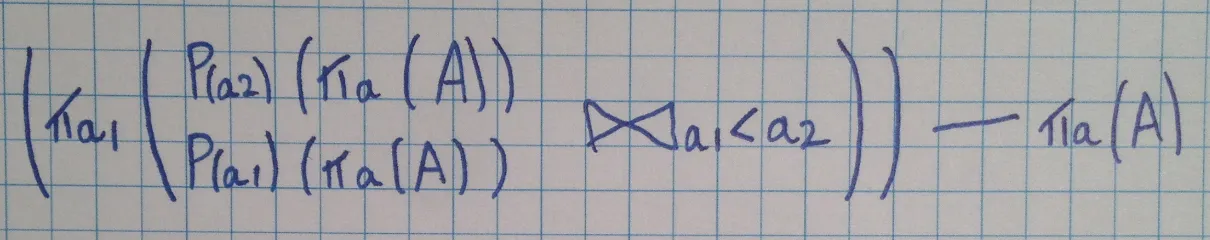
A关系:1、2、3、4
1. First we want to PROJECT and RENAME relation A
2. We then to a THETA JOIN with the test a1<a2
3. We then PROJECT the result of the relation to give us a single set of values
a1: 1,2,3 (not max value since a1<a2)
4. We then apply the difference operator with the original relation so:
1,2,3,4 --- 1,2,3 returns 4
4 is the Max value.
- benscabbia
2
@gudthing 我认为这个公式有误,因为**-**运算符周围的两个表达式应该交换位置。r1(X)和r2(X)的差异表示为r1-r2,并且是X上的关系,包含属于r1但不属于r2的元组。 - alphadog
请使用文本而非图片/链接来呈现文本(包括代码、表格和ERD)。仅在必要时使用图片来补充文本或呈现无法用文本描述的内容。并且不要在没有图例/关键字的情况下给出图表。如果您有足够的声望,请使用编辑功能将内容嵌入到帖子中,而不是链接,使您的帖子自包含。 - philipxy
5
查找最大值:
策略:
找出那些不是最大值的
x。- 将关系
A重命名为d,以便我们可以将每个Ax与其他所有x进行比较。
- 将关系
使用
集合差异来找到在前一步中未找到的那些Ax。
查询语句如下:
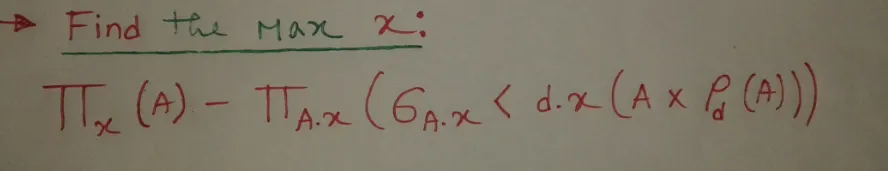
- Md. Rezwanul Haque
2
假设A有另一列
y,并且要求您选择具有最大x的y,您会如何做到这一点?谢谢。 - Zubin Kadva请使用文本而非图片/链接来呈现文本(包括代码、表格和ERD)。仅在必要时使用图片来补充文本或呈现无法用文本表示的内容。并且不要在没有图例/关键字的情况下给出图表。如果您有足够的声望,请使用编辑功能将内容嵌入到帖子中,而不是链接,使您的帖子自包含。 - philipxy
1
Project x(A) - Project A.x
(Select A.x < d.x (A x Rename d(A)))
- Raju
1
关系代数(通过比较进行过滤)
最近在数据库模块的练习材料中遇到了这个问题,当我寻找帮助时,我找不到任何好的答案。 "Md. Rezwanul Haque" 的答案是正确的,但它没有得到很好的解释,因为它依赖于先前的知识(如果您不理解笛卡尔积的话)。
因此,这里是我的解释和答案,希望这能让一些人更容易理解:
TABLE: PEOPLE
PEOPLE.name PEOPLE.age
'Jack' 16
'Megan' 15
'Harry' 14
'Lilly' 16
'Michael' 8
这个想法是:“收集你不想要的并从你拥有的中删除它;留下你想要的。”
步骤1(构建查询表)
在使用SELECTION进行过滤时,我们只能比较我们拥有的元组。这意味着我们需要将我们想要比较的数据添加到这些元组中。
因此,我们需要将PEOPLE表与我们想要比较的数据合并。这可以使用x(笛卡尔积)运算符来完成。
像这样:PEOPLE x PEOPLE,但我们不能这样做,因为结果表看起来会像这样:
TABLE: PEOPLE x PEOPLE
PEOPLE.name PEOPLE.age PEOPLE.name PEOPLE.age
'Jack' 16 'Jack' 16
我们有重复的属性名称,这意味着我们需要创建一个PEOPLE表的副本,它具有不同的名称,以便我们可以引用它。否则,我们无法使用x笛卡尔积运算符,因为它要求结果表中的所有属性都是唯一的,您不能有两个PEOPLE.name属性。
这就是我们将使用RENAME运算符的地方,它看起来像这样:
PEOPLE ⨯ (ρ ALT (PEOPLE))
在这里,我使用笛卡尔积将PEOPLE和ALT合并在一起,其中ALT是PEOPLE重命名为ALT
这将给我们一个类似于这样的表:
TABLE: PEOPLE x ALT
PEOPLE.name PEOPLE.age ALT.name ALT.age
'jack' 16 'jack' 16
'jack' 16 'megan' 15
'jack' 16 'harry' 14
'jack' 16 'lilly' 16
'jack' 16 'michael' 8
第一步(交叉)
我们可以通过将PEOPLE的每个值与ALT的每个值进行比较,生成一个大小为(PEOPLE.size * PEOPLE.size)= 5 * 5的结果表格,其中size是元组数量。
第二步(选择)
现在我们可以过滤所有值并获取我们不想要的值。所以假设我只想要PEOPLE中最年长的人,这个问题可以重新表述为:只有那些不比某人年轻的人,因此我们只抓取那些比某人年轻的人。我们这样做是因为查询我们不想要的比查询我们想要的更容易。
因此,我们的Predicate将是:PEOPLE.age < ALT.age,其中我们仅选择那些比某人年轻的人。
如果我们将Predicate反转为PEOPLE.age > ALT.age,我们将得到一些既不是最年长者,但至少比一个人年长的人。这可以帮助我们获得最年轻的人。
SELECTION:
(σ (PEOPLE.age < ALT.age) (PEOPLE x (ρ ALT (PEOPLE))))
这将生成一个像这样的表格:
TABLE: (σ (PEOPLE.age < ALT.age) (PEOPLE x (ρ ALT (PEOPLE))))
PEOPLE.age PEOPLE.name ALT.name ALT.age
'megan' 15 'jack' 16
'megan' 15 'lilly' 16
'harry' 14 'jack' 16
'harry' 14 'megan' 15
'harry' 14 'lilly' 16
'michael' 8 'jack' 16
'michael' 8 'megan' 15
'michael' 8 'harry' 14
'michael' 8 'lilly' 16
这里的结果是比某人年轻的人,以及他们比谁年轻。然而我们的查询是:只有那些不比某人年轻的人,这正好与此相反。所以这不是我们的目标,我们需要再做一点点工作。如果你这样做:
π PEOPLE.name PEOPLE.age (σ (PEOPLE.age < ALT.age) (PEOPLE x (ρ ALT (PEOPLE))))
这将为我们提供一个包含megan、harry和michael的表格,这是一个由只有比某人年轻的人组成的表格。
步骤3(获取我们的最终表格)
现在我们有了一个由只有比某人年轻的人组成的表格,但我们想要的是只有不比某人年轻的人,所以我们需要做的就是从 PEOPLE 表中删除所有比某人年轻的人,以便仅得到那些不比某人年轻的人。
因此,我们需要使用减法操作从我们的PEOPLE表中删除那些元组。这给出了我们的最终查询:
PEOPLE - (π PEOPLE.name PEOPLE.age (σ (PEOPLE.age < ALT.age) (PEOPLE x (ρ ALT (PEOPLE)))))
这将生成以下表格:
PEOPLE - (π PEOPLE.name PEOPLE.age (σ (PEOPLE.age < ALT.age) (PEOPLE x (ρ ALT (PEOPLE)))))
PEOPLE.name PEOPLE.age
'jack' 16
'lilly' 16
杰克和莉莉是 PEOPLE 中唯一不比任何人年轻的人。
- Ry-
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接