我完成了一个项目,其中我从用记事本编写的文本文件中读取了内容。我的文本文件中的字符是阿拉伯语,并且文件编码类型为UTF-8。在Netbeans(7.0.1)中启动我的项目时一切都正常,但是当我将项目构建为.jar文件后,字符以这种方式显示:ÇáãæÇÞÚááÊØæíÑ。请问我该如何解决这个问题?
2个回答
4
很可能您在某处使用了JVM默认的字符编码。如果您100%确定文件是使用UTF-8编码的,请确保在读取时明确指定UTF-8。例如,以下代码是错误的:
new FileReader("file.txt")
因为它使用JVM默认字符编码 - 你可能无法控制,而Netbeans显然使用UTF-8,而你的操作系统定义了不同的内容。请注意,如果您希望您的代码可移植,这使得
FileReader类完全无用。相反,请使用以下代码片段:
new InputStreamReader(new FileInputStream("file.txt"), "UTF-8");
您没有提供代码,但这应该可以给您一个大致的印象,应该如何实现。
- Tomasz Nurkiewicz
2
也许这个例子可以帮助一点。我将尝试打印utf-8文件的内容到IDE控制台和编码为"Cp852"的系统控制台。
我的d:\data.txt包含ąźżćąś adsfasdf
让我们检查一下这段代码。
当我在Eclipse中运行它,输出将是:
但是来自系统控制台的输出将会是:
我的d:\data.txt包含ąźżćąś adsfasdf
让我们检查一下这段代码。
//I will read chars using utf-8 encoding
BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream("d:\\data.txt"), "utf-8"));
//and write to console using Cp852 encoding (works for my windows7 console)
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out,
"Cp852"),true); // "Cp852" is coding used in
// my console in Win7
// ok, lets read data from file
String line;
while ((line = in.readLine()) != null) {
// here I use IDE encoding
System.out.println(line);
// here I print data using Cp852 encoding
out.println(line);
}
当我在Eclipse中运行它,输出将是:
ąźżćąś adsfasdf
Ą«ľ†Ą? adsfasdf
但是来自系统控制台的输出将会是:
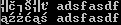
- Pshemo
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接