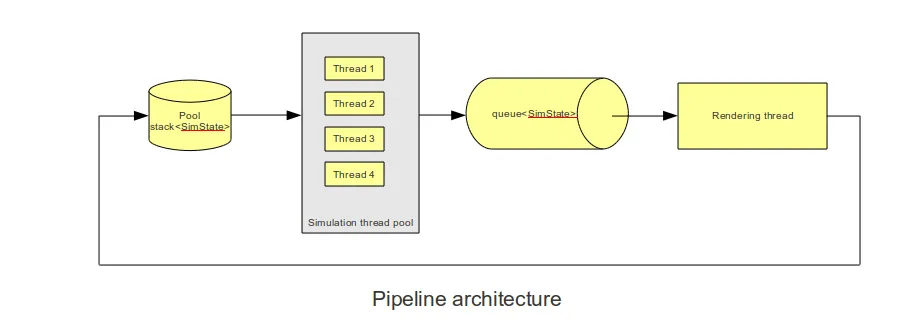
我的应用程序由两个线程组成:
在我的GUI线程中,我以30-60帧的FPS渲染Sim中的实体;然而,我希望我的Sim能够“向前推进” - 所谓的 - 并排队等待游戏状态最终被绘制出来(类似于流媒体视频,你有一个缓冲区)。
现在对于我渲染的每一帧Sim,我需要相应的模拟“状态”。因此,我的Sim线程看起来像这样:
在当前设置下,模拟无法比GUI线程绘制得更快。我已经验证了当前瓶颈是
那么,我应该使用哪些容器来存储模拟状态?我知道目前存在大量复制,但其中一些是不可避免的。我应该在向量中存储
注意:实际上,模拟不在一个循环中,而是使用Qt的
- GUI线程(使用Qt)
- 模拟线程
在我的GUI线程中,我以30-60帧的FPS渲染Sim中的实体;然而,我希望我的Sim能够“向前推进” - 所谓的 - 并排队等待游戏状态最终被绘制出来(类似于流媒体视频,你有一个缓冲区)。
现在对于我渲染的每一帧Sim,我需要相应的模拟“状态”。因此,我的Sim线程看起来像这样:
while(1) {
simulation.update();
SimState* s = new SimState;
simulation.getAgents( s->agents ); // store agents
// store other things to SimState here..
stateStore.enqueue(s); // stateStore is a QQueue<SimState*>
if( /* some threshold reached */ )
// push stateStore
}
SimState看起来像这样:
struct SimState {
std::vector<Agent> agents;
//other stuff here
};
而Simulation::getAgents看起来像:
void Simulation::getAgents(std::vector<Agent> &a) const
{
// mAgents is a std::vector<Agent>
std::vector<Agent> a_tmp(mAgents);
a.swap(a_tmp);
}
Agent类本身是一些相对复杂的类。成员包括一些int和float以及两个std::vector<float>。在当前设置下,模拟无法比GUI线程绘制得更快。我已经验证了当前瓶颈是
simulation.getAgents(s->agents),因为即使我省略了推送更新,每秒的更新速度也很慢。如果我注释掉那行代码,我会看到更新/秒有几个数量级的改善。那么,我应该使用哪些容器来存储模拟状态?我知道目前存在大量复制,但其中一些是不可避免的。我应该在向量中存储
Agent*而不是Agent吗?注意:实际上,模拟不在一个循环中,而是使用Qt的
QMetaObject::invokeMethod(this, "doSimUpdate", Qt::QueuedConnection);,所以我可以使用信号/插槽在线程之间通信;然而,我已经验证了一个简单版本,使用while(1){},问题仍然存在。