我最近开始使用 Haskell,很可能只会用一小段时间。只是因为我在上大学的一个课程中被要求使用它来更好地理解函数式编程。
现在我遇到了一个小问题。我正在尝试按广度优先的方式构建它,但我觉得我的条件有些混乱,或者我的条件也可能是错误的。
因此,如果我输入
[“A1-Gate”, “North-Region”, “South-Region”, “Convention Center”, “Rectorate”, “Academic Building1”, “Academic Building2”] 和 [0.0, 0.5, 0.7, 0.3, 0.6, 1.2, 1.4, 1.2],我的树应该像这样:
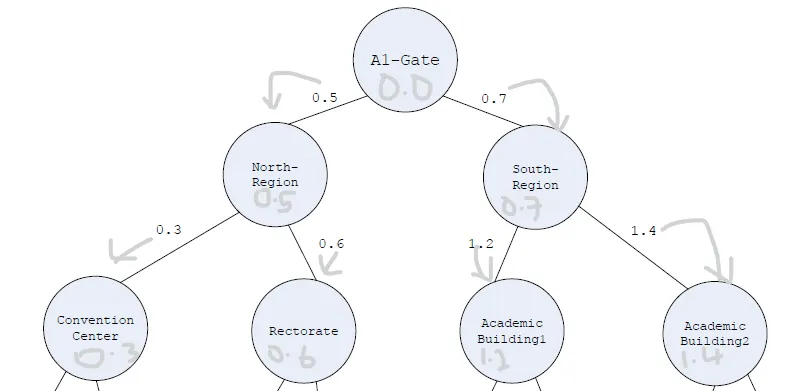
但我的测试结果并不是我预期的。所以一个有经验的 Haskell 专家可能会帮助我发现我做错了什么。
输出:
*Main> l1 = ["A1-Gate", "North-Region", "South-Region", "Convention Center",
"Rectorate", "Academic Building1", "Academic Building2"]
*Main> l3 = [0.0, 0.5, 0.7, 0.3, 0.6, 1.2, 1.4, 1.2]
*Main> parkingtree = createBinaryParkingTree l1 l3
*Main> parkingtree
Node "North-Region" 0.5
(Node "A1-Gate" 0.0 EmptyTree EmptyTree)
(Node "Convention Center" 0.3
(Node "South-Region" 0.7 EmptyTree EmptyTree)
(Node "Academic Building2" 1.4
(Node "Academic Building1" 1.2 EmptyTree EmptyTree)
(Node "Rectorate" 0.6 EmptyTree EmptyTree)))
A-1门应该是根,但它最终成为一个没有子级的子级,因此条件非常混乱。
如果我能得到一些指导,会很有帮助。以下是我目前写的内容:
data Tree = EmptyTree | Node [Char] Float Tree Tree deriving (Show,Eq,Ord)
insertElement location cost EmptyTree =
Node location cost EmptyTree EmptyTree
insertElement newlocation newcost (Node location cost left right) =
if (left == EmptyTree && right == EmptyTree)
then Node location cost (insertElement newlocation newcost EmptyTree)
right
else if (left == EmptyTree && right /= EmptyTree)
then Node location cost (insertElement newlocation newcost EmptyTree)
right
else if (left /= EmptyTree && right == EmptyTree)
then Node location cost left
(insertElement newlocation newcost EmptyTree)
else Node newlocation newcost EmptyTree
(Node location cost left right)
buildBPT [] = EmptyTree
--buildBPT (xs:[]) = insertElement (fst xs) (snd xs) (buildBPT [])
buildBPT (x:xs) = insertElement (fst x) (snd x) (buildBPT xs)
createBinaryParkingTree a b = buildBPT (zip a b)
感谢提供任何可能的帮助。是的,我已经查看了一些类似的问题,但我认为我的问题是不同的,但如果您认为某篇文章有明确的答案可以帮助我,我愿意去看看。
bfst(Xs,T):- bfst(Xs,[T|R],R). bfst(Xs,Ns,Z):- Xs=[] -> Z=[], maplist(=(empty),Ns) ; Xs=[X|Xs2], Ns=[node(X,L,R)|Ns2], Z=[L,R|Z2], bfst(Xs2,Ns2,Z2)。- Will Ness