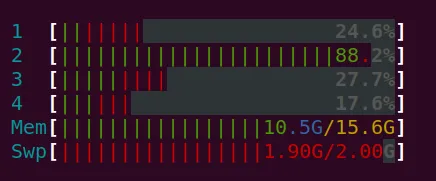
身份列表包含大约57000张图片的大数组。现在,我正在使用itertools.product()创建一个负面列表。这将整个列表保存在内存中,非常昂贵,我的系统在4分钟后挂起。
如何优化下面的代码并避免在内存中保存?
for i in range(0, len(idendities) - 1):
for j in range(i + 1, len(idendities)):
cross_product = itertools.product(samples_list[i], samples_list[j])
cross_product = list(cross_product)
for cross_sample in cross_product:
negative = []
negative.append(cross_sample[0])
negative.append(cross_sample[1])
negatives.append(negative)
print(len(negatives))
negatives = pd.DataFrame(negatives, columns=["file_x", "file_y"])
negatives["decision"] = "No"
negatives = negatives.sample(positives.shape[0])
内存使用率将越来越高,某一点系统会完全挂起。
我还根据下面的答案实现了以下代码修改。
for i in range(0, len(idendities) - 1):
for j in range(i + 1, len(idendities)):
for cross_sample in itertools.product(samples_list[i], samples_list[j]):
negative = [cross_sample[0], cross_sample[1]]
negatives.append(negative)
print(len(negatives))
negatives = pd.DataFrame(negatives, columns=["file_x", "file_y"])
negatives["decision"] = "No"
代码的第三个版本
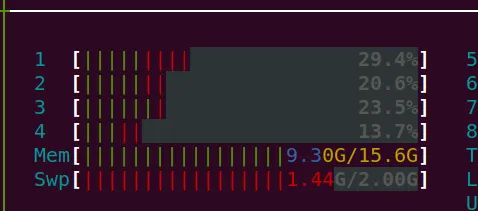
这个CSV文件太大了,即使你打开一个文件,它也会弹出一个警告说你的程序无法加载所有文件。关于这个过程,需要十分钟左右,然后系统再次完全挂起。
for i in range(0, len(idendities) - 1):
for j in range(i + 1, len(idendities)):
for cross_sample in itertools.product(samples_list[i], samples_list[j]):
with open('/home/khawar/deepface/tests/results.csv', 'a+') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([cross_sample[0], cross_sample[1]])
negative = [cross_sample[0], cross_sample[1]]
negatives.append(negative)
negatives = pd.DataFrame(negatives, columns=["file_x", "file_y"])
negatives["decision"] = "No"
negatives = negatives.sample(positives.shape[0])
内存截图。