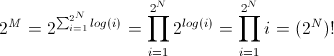https://github.com/yaojingguo/subsets提供了两个算法来解决子集问题。 Iter算法与问题中给出的代码相同。 Recur算法使用递归访问每个可能的子集。两种算法的时间复杂度均为Θ(n*2^n)。在Iter算法中,1语句执行n*2^n次。 2语句执行n*2^(n-1)次(基于@templatetypedef的分析)。使用a表示1的成本。并使用b表示2的成本。总成本为n*2^n*a + n*2^(n-1)*b。
if ((i & (1 << j)) > 0) // 1
list.add(A[j]); // 2
这里是
Recur算法的主要逻辑:
result.add(new ArrayList<Integer>(list));
for (int i = pos; i < num.length; i++) {
list.add(num[i]);
dfs(result, list, num, i + 1);
list.remove(list.size() - 1);
}
语句 3 的代价与 1 相同,都是 n*2^(n-1)*b。其它的代价在循环 4 中。每次循环迭代包括三个函数调用。总共执行了 2^n 次循环。用 d 表示 4 的代价。总代价是 2^n*d + n*2^(n-1)*b。下面的图是集合 {1, 2, 3, 4} 对应的递归树。更精确的分析需要单独处理 2^(n-1) 个叶子节点。
Ø --- 1 --- 2 --- 3 --- 4
| | |- 4
| |- 3 --- 4
| |- 4
|- 2 --- 3 --- 4
| |- 4
|- 3 --- 4
|- 4
比较这两个算法的复杂度就是比较式子(1)的
n*2^n*a 和式子(2)的
2^n*d。将式子(1)除以式子(2),得到
n * a / d。如果
n*a 小于
d,那么
Iter比
Recur更快。我使用
Driver来测试这两个算法的效率。以下是一次运行的结果:
n: 16
Iter mills: 40
Recur mills: 19
n: 17
Iter mills: 78
Recur mills: 32
n: 18
Iter mills: 112
Recur mills: 10
n: 19
Iter mills: 156
Recur mills: 149
n: 20
Iter mills: 563
Recur mills: 164
n: 21
Iter mills: 2423
Recur mills: 1149
n: 22
Iter mills: 7402
Recur mills: 2211
这表明对于较小的n,Recur比Iter更快。