微服务架构试图让组织拥有小团队独立开发和运行服务的能力。具体请参见
read。最难的部分在于以有用的方式定义服务边界。当你发现应用程序的拆分方式导致需求经常影响多个服务时,这会提示您重新考虑服务边界。当你感觉需要在服务之间共享实体时,也是如此。
因此,一般建议尽可能避免这种情况。然而,可能有些情况下你无法避免它。由于良好的架构通常涉及做出正确的权衡,在这里提供一些想法。
考虑使用服务接口(API)而不是直接的数据库依赖来表达依赖关系。这将允许每个服务团队根据需要更改其内部数据架构,并且只需要在依赖项方面担心接口设计。这非常有帮助,因为添加其他API并逐渐淘汰旧API比同时更改DB设计以及所有相关微服务要容易得多。换句话说,只要支持旧API,您仍然能够独立部署新的微服务版本。这是亚马逊CTO推荐的方法,他是微服务方法的先锋。这里建议阅读他在2006年的
interview。
当你真的无法避免使用相同的数据库并且你正在以多个团队/服务需要相同实体的方式划分你的服务边界时,你引入了两个依赖于微服务团队和负责数据架构的团队之间的依赖关系: a)数据格式,b)实际数据。这不是不可能解决的,但组织上需要一些额外的开销。如果引入太多这样的依赖性,您的组织在开发中很可能会变得瘫痪和缓慢。
a) 数据方案的依赖性。实体数据格式不能在不需要更改微服务的情况下进行修改。为了解耦,您需要严格版本化实体数据方案,并在数据库中支持微服务当前正在使用的所有数据版本。这将允许微服务团队自行决定何时更新其服务以支持新版本的数据方案。虽然这在所有用例中都不可行,但它适用于许多用例。
b) 实际收集数据的依赖性。已知版本的微服务可以使用已收集的数据,但问题出现在某些服务生成了新版本的数据,而另一个服务依赖于它-但尚未升级以能够读取最新版本。这个问题很难解决,在许多情况下表明您没有正确选择服务边界。通常,您别无选择,只能在升级数据库中的数据时同时推出所有依赖数据的服务。一种更奇怪的方法是同时编写不同版本的数据(当数据不可变时,这种方法大多有效)。
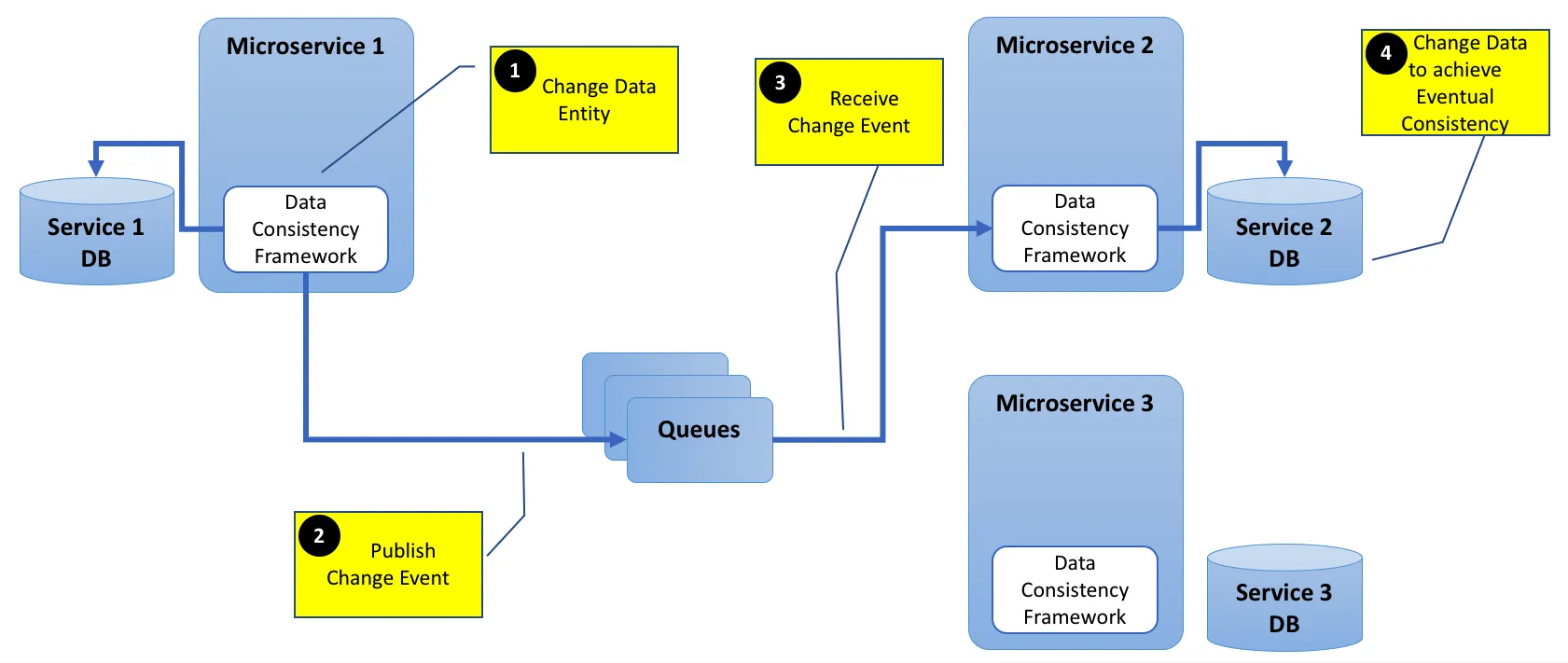
为了解决a)和b)中的某些情况,可以通过隐藏数据复制和最终一致性来减少依赖关系。这意味着每个服务都存储其自己版本的数据,并且仅在该服务的要求发生变化时才进行修改。服务可以通过监听公共数据流来实现这一点。在这种情况下,您将使用基于事件的架构,其中定义了一组公共事件,可以排队并由来自不同服务的侦听器消耗,这些服务将处理事件并存储其中与其相关的任何数据(可能会创建数据复制)。现在,其他一些事件可能表明必须更新内部存储的数据,每个服务都有责任使用其自己的数据副本进行更新。维护这样的公共事件队列的技术是
Kafka。