你如何显示Unicode字符串,比如:
x <- "•"
使用其转义等效形式吗?
y <- "\u2022"
identical(x, y)
# [1] TRUE
我希望能够这样做,因为CRAN包必须只包含ASCII字符,但有时您想在错误消息或类似情况下使用unicode。
你如何显示Unicode字符串,比如:
x <- "•"
使用其转义等效形式吗?
y <- "\u2022"
identical(x, y)
# [1] TRUE
我希望能够这样做,因为CRAN包必须只包含ASCII字符,但有时您想在错误消息或类似情况下使用unicode。
在阅读了一些关于iconv的文档后,我认为你可以仅使用base软件包来实现此操作。但是你需要特别注意字符串的编码。
在一个UTF-8编码的系统上:
> stri_escape_unicode("你好世界")
[1] "\\u4f60\\u597d\\u4e16\\u754c"
# use big endian
> iconv(x, "UTF-8", "UTF-16BE", toRaw=T)
[[1]]
[1] 4f 60 59 7d 4e 16 75 4c
> x <- "•"
> iconv(x, "UTF-8", "UTF-16BE", toRaw=T)
[[1]]
[1] 20 22
但是,如果您使用的系统采用 latin1 编码,则可能会出现问题。
> x <- "•"
> y <- "\u2022"
> identical(x, y)
[1] FALSE
> stri_escape_unicode(x)
[1] "\\u0095" # <- oops!
# culprit
> Encoding(x)
[1] "latin1"
# and it causes problem for iconv
> iconv(x, Encoding(x), "Unicode")
Error in iconv(x, Encoding(x), "Unicode") :
unsupported conversion from 'latin1' to 'Unicode' in codepage 1252
> iconv(x, Encoding(x), "UTF-16BE")
Error in iconv(x, Encoding(x), "UTF-16BE") :
embedded nul in string: '\0•'
> iconv(enc2utf8(enc2native(x)), "UTF-8", "UTF-16BE", toRaw=T)
[[1]]
[1] 20 22
编辑:这可能会对某些特定系统上已经使用UTF-8编码的字符串造成问题。在转换之前检查编码可能更安全。
> Encoding("•")
[1] "latin1"
> enc2native("•")
[1] "•"
> enc2native("\u2022")
[1] "•"
# on a Windows with default latin1 encoding
> Encoding("测试")
[1] "UTF-8"
> enc2native("测试")
[1] "<U+6D4B><U+8BD5>" # <- BAD!
对于一些字符或语言来说,UTF-16 可能不够用。因此,你应该使用 UTF-32。
UTF-32形式的字符是其代码点的直接表示。
基于以上试验和错误,下面是我们可以编写的一个比较安全的转义函数:
unicode_escape <- function(x, endian="big") {
if (Encoding(x) != 'UTF-8') {
x <- enc2utf8(enc2native(x))
}
to.enc <- ifelse(endian == 'big', 'UTF-32BE', 'UTF-32LE')
bytes <- strtoi(unlist(iconv(x, "UTF-8", "UTF-32BE", toRaw=T)), base=16)
# there may be some better way to do thibs.
runes <- matrix(bytes, nrow=4)
escaped <- apply(runes, 2, function(rb) {
nonzero.bytes <- rb[rb > 0]
ifelse(length(nonzero.bytes) > 1,
# convert back to hex
paste("\\u", paste(as.hexmode(nonzero.bytes), collapse=""), sep=""),
rawToChar(as.raw(nonzero.bytes))
)
})
paste(escaped, collapse="")
}
> unicode_escape("•••ERROR!!!•••")
[1] "\\u2022\\u2022\\u2022ERROR!!!\\u2022\\u2022\\u2022"
> unicode_escape("Hello word! 你好世界!")
[1] "Hello word! \\u4f60\\u597d\\u4e16\\u754c!"
> "\u4f60\u597d\u4e16\u754c"
[1] "你好世界"
iconv 是可以的。另一个答案使用了 stri_escape_unicode,我只是想表明您不必使用 stri_escape_unicode。 - Xin Yinstringi 软件包有一种方法可以实现这个功能。
stri_escape_unicode(y)
# [1] "\\u2022"
stringi会有这个功能! - hadleyuniscape,可以将非ASCII字符转换为相应的"\u1234"或"\U12345678" Unicode转义代码(显然带有反斜杠)。它可以为任何字符转换,也可以仅为R字符串内的字符(单引号或双引号)转换。以下示例显示了u_escape如何转换字符。输出结果被括在引号中,解析并评估。最终结果与原始字符匹配。x <- rawToChar(as.raw(c(0xe2, 0x80, 0xa2)))
Encoding(x) <- "UTF-8"
x
# [1] "•"
x_u <- uniscape::u_escape(x)
x_u
# [1] "\\u2022"
y <- eval(parse(text = paste0('"', x_u, '"')))
y
# [1] "•"
identical(x, y)
# [1] TRUE
rstudioapi之外没有任何硬性依赖。uniscape插件。选择了“Escape selection”插件。
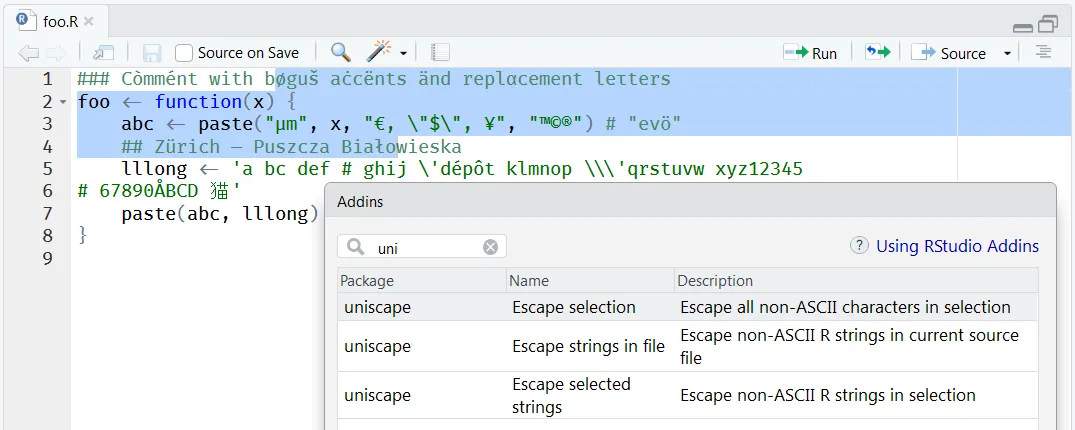 应用“Escape selection”后,每个非ASCII字符的编码序列会自动高亮(选定),如下图所示。
应用“Escape selection”后,每个非ASCII字符的编码序列会自动高亮(选定),如下图所示。
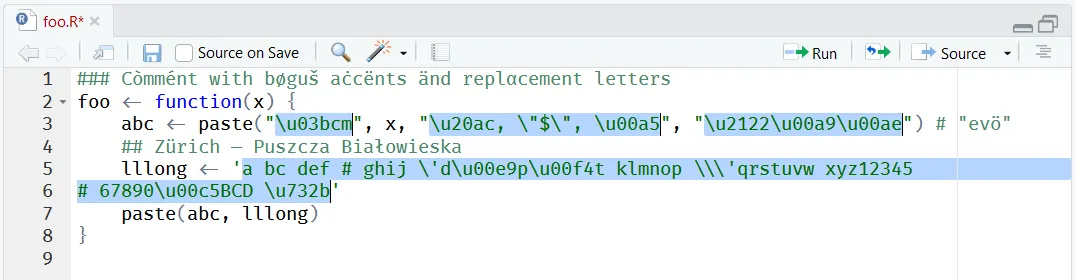
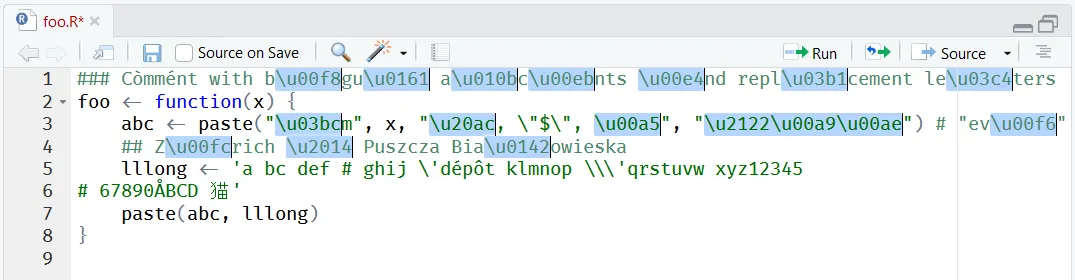 撤销之前的操作后,“在文件中转义字符串”的结果如下。活动文件中受影响的每个R字符串都会自动被插件突出显示。注释的字符串将被忽略。“转义选定字符串”执行相同的操作,但仅针对所选文本区域。
撤销之前的操作后,“在文件中转义字符串”的结果如下。活动文件中受影响的每个R字符串都会自动被插件突出显示。注释的字符串将被忽略。“转义选定字符串”执行相同的操作,但仅针对所选文本区域。
R在C语言环境中自动转义Unicode:
x <- "•"
Sys.setlocale(locale = 'C')
print(x)
# [1] "<U+2022>"
identical(x, y)函数,结果并不是不变的。在Windows机器上使用答案中的stri_escape_unicode函数:stri_escape_unicode(x)会产生"\\u0095"的结果。编辑:好吧,这与编码有关。 - Xin Yin