我做了一个简单的实验,通过实现朴素字符搜索算法在CPU和GPU上(使用iOS8的Metal计算管道)搜索1,000,000行每行50个字符的简单数据(共5,000万个字符映射)。
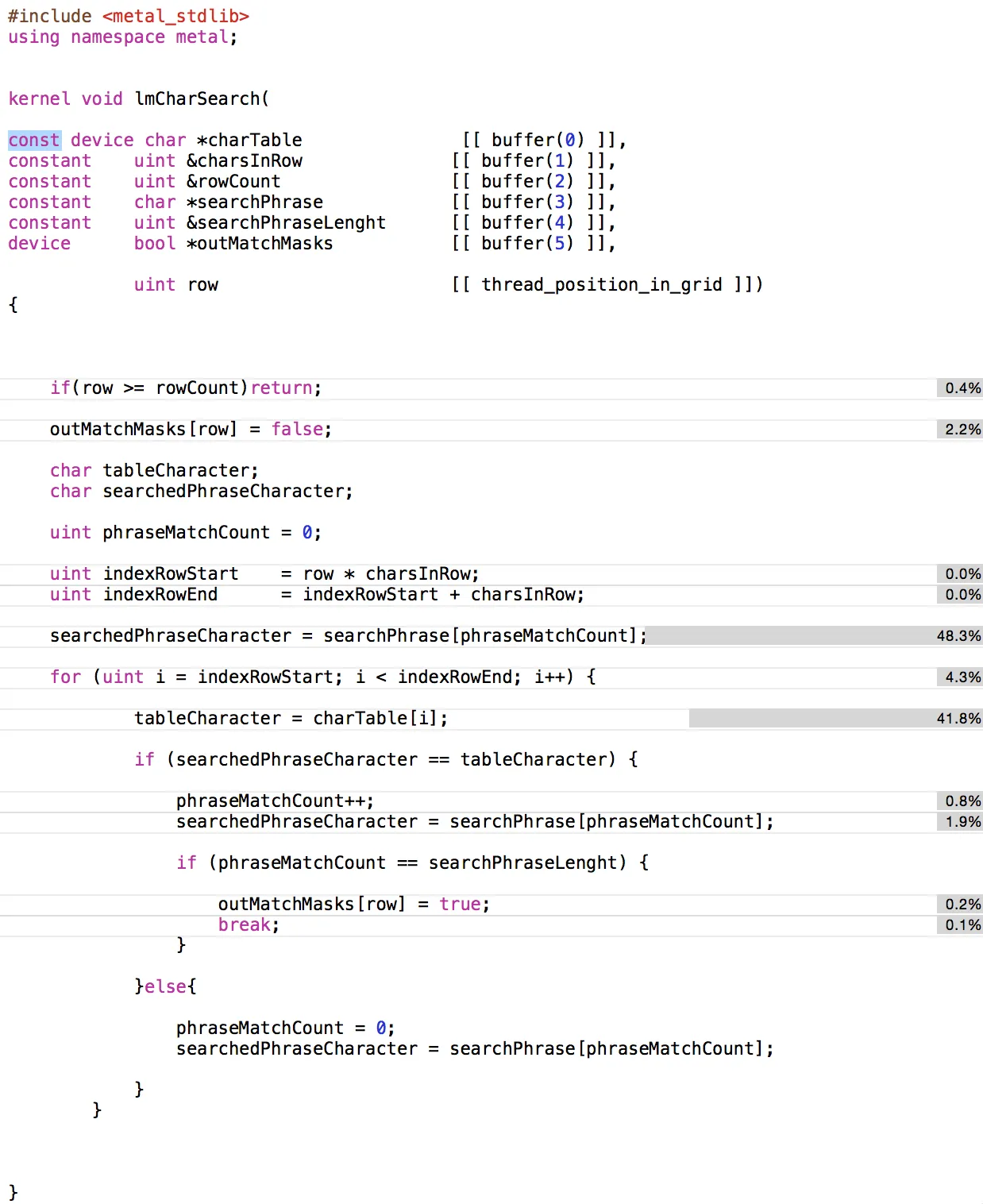
CPU实现使用简单循环,Metal实现为每个内核提供1行进行处理(以下是源代码)。
令我惊讶的是,如果我只使用1个核心,那么平均而言,Metal实现比简单的线性CPU慢2-3倍;如果我使用2个核心(每个核心搜索一半数据库),则慢3-4倍!我尝试了不同的线程组(16、32、64、128、512),但仍然得到非常相似的结果。
iPhone 6:
CPU 1 core: approx 0.12 sec
CPU 2 cores: approx 0.075 sec
GPU: approx 0.35 sec (relEase mode, validation disabled)
我可以看到Metal着色器使用超过90%的时间来访问内存(见下文)。
有什么优化的方法吗?
任何见解都将不胜感激,因为互联网上没有太多来源(除了标准的Apple编程指南),提供有关Metal框架特定的内存访问内部和权衡的详细信息。
METAL实现细节:
主机代码要点:https://gist.github.com/lukaszmargielewski/0a3b16d4661dd7d7e00d
内核(着色器)代码:https://gist.github.com/lukaszmargielewski/6b64d06d2d106d110126
GPU帧捕获分析结果: