我正在尝试查询一些趋势统计数据,但是基准测试非常慢。查询执行时间大约为134秒。
我有一个名为table_1的MySQL表。
以下是创建语句:
CREATE TABLE `table_1` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`original_id` bigint(11) DEFAULT NULL,
`invoice_num` bigint(11) DEFAULT NULL,
`registration` timestamp NULL DEFAULT NULL,
`paid_amount` decimal(10,6) DEFAULT NULL,
`cost_amount` decimal(10,6) DEFAULT NULL,
`profit_amount` decimal(10,6) DEFAULT NULL,
`net_amount` decimal(10,6) DEFAULT NULL,
`customer_id` bigint(11) DEFAULT NULL,
`recipient_id` text,
`cashier_name` text,
`sales_type` text,
`sales_status` text,
`sales_location` text,
`invoice_duration` text,
`store_id` double DEFAULT NULL,
`is_cash` int(11) DEFAULT NULL,
`is_card` int(11) DEFAULT NULL,
`brandid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_registration_compound` (`id`,`registration`)
) ENGINE=InnoDB AUTO_INCREMENT=47420958 DEFAULT CHARSET=latin1;
我设置了一个由id+registration组成的复合索引。
以下是查询语句
SELECT
store_id,
CONCAT('[',GROUP_CONCAT(tot SEPARATOR ','),']') timeline_transactions,
SUM(tot) AS total_transactions,
CONCAT('[',GROUP_CONCAT(totalRevenues SEPARATOR ','),']') timeline_revenues,
SUM(totalRevenues) AS revenues,
CONCAT('[',GROUP_CONCAT(totalProfit SEPARATOR ','),']') timeline_profit,
SUM(totalProfit) AS profit,
CONCAT('[',GROUP_CONCAT(totalCost SEPARATOR ','),']') timeline_costs,
SUM(totalCost) AS costs
FROM (select t1.md,
COALESCE(SUM(t1.amount+t2.revenues), 0) AS totalRevenues,
COALESCE(SUM(t1.amount+t2.profit), 0) AS totalProfit,
COALESCE(SUM(t1.amount+t2.costs), 0) AS totalCost,
COALESCE(SUM(t1.amount+t2.tot), 0) AS tot,
t1.store_id
from
(
SELECT a.store_id,b.md,b.amount from ( SELECT DISTINCT store_id FROM table_1) AS a
CROSS JOIN
(
SELECT
DATE_FORMAT(a.DATE, "%m") as md,
'0' as amount
from (
select curdate() - INTERVAL (a.a + (10 * b.a) + (100 * c.a)) month as Date
from (select 0 as a union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) as a
cross join (select 0 as a union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) as b
cross join (select 0 as a union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) as c
) a
where a.Date >='2019-01-01' and a.Date <= '2019-01-14'
group by md) AS b
)t1
left join
(
SELECT
COUNT(epl.invoice_num) AS tot,
SUM(paid_amount) AS revenues,
SUM(profit_amount) AS profit,
SUM(cost_amount) AS costs,
store_id,
date_format(epl.registration, '%m') md
FROM table_1 epl
GROUP BY store_id, date_format(epl.registration, '%m')
)t2
ON t2.md=t1.md AND t2.store_id=t1.store_id
group BY t1.md, t1.store_id) AS t3 GROUP BY store_id ORDER BY total_transactions desc
以下是EXPLAIN的内容
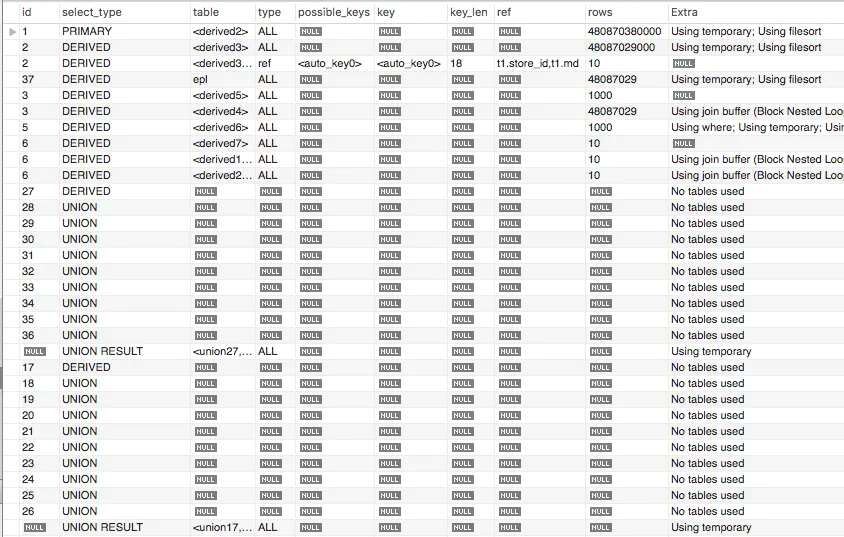
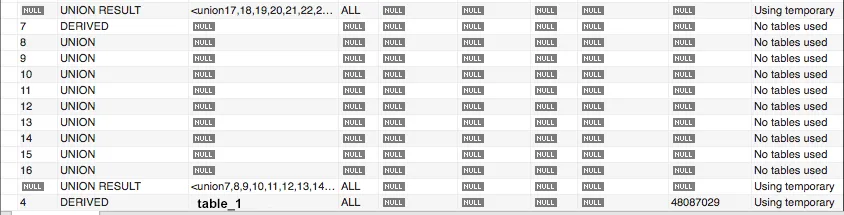
也许我应该将registration列中的时间戳更改为日期时间?
- innodb_buffer_pool_size是用于缓存表、索引和其他一些东西的内存量。
- 你可以在MySQL中配置多个innodb_buffer_pool_instances来增加读/写线程。
尝试从查询中删除order by或设置适当的索引。更多详情请参考以下网站:- https://www.percona.com/blog/2014/01/28/10-mysql-performance-tuning-settings-after-installation/
- https://www.saotn.org/mysql-innodb-performance-improvement/
- Priyesh