我该如何计算一列中两个值之间的差异?
计算应从前两个值开始,并且应像在“desired_result”列中所做的那样继续下一个两个值的计算:
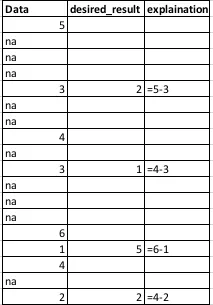
data <- data.frame(data = c(5, NA, NA, NA, 3, NA, NA, 4, NA, 3, NA, NA, NA, 6, 1, 4, NA, 2))
我该如何计算一列中两个值之间的差异?
计算应从前两个值开始,并且应像在“desired_result”列中所做的那样继续下一个两个值的计算:
data <- data.frame(data = c(5, NA, NA, NA, 3, NA, NA, 4, NA, 3, NA, NA, NA, 6, 1, 4, NA, 2))
以下是一行代码:
data$desired_result[which(!is.na(data$data))[c(FALSE, TRUE)]] <-
rev(diff(rev(na.omit(data$data))))[c(TRUE, FALSE)]
which(!is.na(data$data))会找到data$data中的非NA条目,然后添加c(FALSE,TRUE)只选择每隔一个条目。另外,na.omit(data$data)丢弃NA值,rev 反转该向量,diff取差分,rev再次反转向量以恢复正确顺序,最后,因为我们不需要所有的差异,我再次使用c(TRUE,FALSE) 选择每隔一个条目。
与Julius相同,但更短更快:
data$desired_result[which(!is.na(data$data))[c(FALSE, TRUE)]] <-
diff(na.omit(data$data))[c(TRUE, FALSE)] * -1
由于diff()计算的是x1 - x0,因此可以使用diff() * -1来替换rev()
使用微基准测试进行速度比较:
Unit: microseconds
expr min lq mean median uq max neval cld
julius 38.096 43.757 51.44687 46.143 50.8655 170511.851 1e+05 b
this 32.828 37.501 43.02233 39.548 43.4390 7405.489 1e+05 a
如果你想要一个与你在这里描述的完全相同的结果,你可以使用:
> data <- data.frame(data = c(5, NA, NA, NA, 3, NA, NA, 4, NA, 3, NA,
> NA, NA, 6, 1, 4, NA, 2)) %>% mutate(index = 1:n())
>
> ex = data %>% filter(!is.na(data))
>
> df2 = data.frame(index = rollapply(ex$index, width = 2, by = 2, last),
> desired_results = rollapply(ex$data, width = 2, by = 2, FUN = function (x) -1*diff(x)))
>
> data2 = left_join(data, df2, by = "index") %>% select(-index)
data desired_results
1 5 NA
2 NA NA
3 NA NA
4 NA NA
5 3 2
6 NA NA
7 NA NA
8 4 NA
9 NA NA
10 3 1
11 NA NA
12 NA NA
13 NA NA
14 6 NA
15 1 5
16 4 NA
17 NA NA
18 2 2
但如果你只想知道它们的不同,那么你可以使用:
rollapply(na.omit(data$data), by = 2, width = 2, diff)
请注意,您将会得到负数结果:-2 -1 -5 -2
zoo::na.locf、ifelse,再加上一点逻辑粘合来完成它。 - r2evansNA值,然后简单地使用diff函数? - tstudio