我的句子是:
编辑 此外,当我使用下面的代码搜索标签时,5-FU被显示为NN。如果Spacy的注释将这个单词理解为由介词包围的名词,那么为什么这个单词不能被识别为名词短语呢? 结束编辑
我的spacy版本: 我做错了什么?displaCy和我使用的版本之间是否有版本差异?是否有一个spaCy帮助团队来解决这个问题?
我做错了什么?displaCy和我使用的版本之间是否有版本差异?是否有一个spaCy帮助团队来解决这个问题?
非常感谢!
在这个方案之前,她有一个单独使用5-FU的化疗方案历史,没有任何显著的副作用。
当我将此输入displacy(https://demos.explosion.ai/displacy/)时,输出包含对5-FU的名词短语引用。
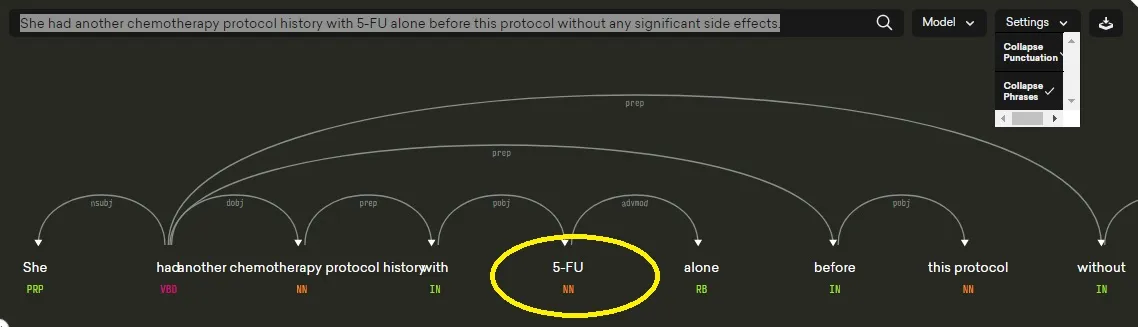
编辑 此外,当我使用下面的代码搜索标签时,5-FU被显示为NN。如果Spacy的注释将这个单词理解为由介词包围的名词,那么为什么这个单词不能被识别为名词短语呢? 结束编辑
我的spacy版本:
我做错了什么?displaCy和我使用的版本之间是否有版本差异?是否有一个spaCy帮助团队来解决这个问题?非常感谢!
