int[] myIntegers;
myIntegers = new int[100];
数组、堆、栈和值类型
155
- devoured elysium
8个回答
338
你的数组是在堆上分配的,而int类型没有装箱(boxed)。
你感到困惑的原因可能是因为人们说引用类型(reference types)在堆上分配,值类型(value types)在栈上分配。这并不是完全准确的表述。
所有局部变量和参数都分配在栈上,包括值类型和引用类型。两者之间的区别只在于变量中存储的内容。对于值类型,类型的值直接存储在变量中,而对于引用类型,类型的值存储在堆上,变量中存储的是指向该值的引用。
字段也是同样的情况。当为聚合类型(an aggregate type,如class或struct)的实例分配内存时,必须包括每个实例字段的存储空间。对于引用类型字段,该存储空间仅保存对该值的引用,该值本身稍后将在堆上分配。而对于值类型字段,该存储空间保存实际的值。
所以,考虑以下类型:
class RefType{
public int I;
public string S;
public long L;
}
struct ValType{
public int I;
public string S;
public long L;
}
0 ┌───────────────────┐ │ I │ 4 ├───────────────────┤ │ S │ 8 ├───────────────────┤ │ L │ │ │ 16 └───────────────────┘现在,如果您在函数中有三个本地变量,类型分别为RefType、ValType和int[],就像这样:
RefType refType;
ValType valType;
int[] intArray;
那么你的栈可能看起来像这样:
0 ┌───────────────────┐ │ refType │ 4 ├───────────────────┤ │ valType │ │ │ │ │ │ │ 20 ├───────────────────┤ │ intArray │ 24 └───────────────────┘
如果你给这些本地变量分配了值,就像这样:
refType = new RefType();
refType.I = 100;
refType.S = "refType.S";
refType.L = 0x0123456789ABCDEF;
valType = new ValType();
valType.I = 200;
valType.S = "valType.S";
valType.L = 0x0011223344556677;
intArray = new int[4];
intArray[0] = 300;
intArray[1] = 301;
intArray[2] = 302;
intArray[3] = 303;
йӮЈд№ҲдҪ зҡ„е Ҷж ҲеҸҜиғҪзңӢиө·жқҘеғҸиҝҷж ·:
0 в”Ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”җ в”Ӯ 0x4A963B68 в”Ӯ -- `refType` зҡ„е Ҷең°еқҖ 4 в”ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Ө в”Ӯ 200 в”Ӯ -- `valType.I` зҡ„еҖј в”Ӯ 0x4A984C10 в”Ӯ -- `valType.S` зҡ„е Ҷең°еқҖ в”Ӯ 0x44556677 в”Ӯ -- `valType.L` зҡ„дҪҺ32дҪҚ в”Ӯ 0x00112233 в”Ӯ -- `valType.L` зҡ„й«ҳ32дҪҚ 20 в”ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Ө в”Ӯ 0x4AA4C288 в”Ӯ -- `intArray` зҡ„е Ҷең°еқҖ 24 в””в”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”ҳ
ең°еқҖдёә0x4A963B68пјҲеҚіrefTypeзҡ„еҖјпјүзҡ„еҶ…еӯҳдјҡеғҸиҝҷж ·:
0 в”Ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”җ в”Ӯ 100 в”Ӯ -- `refType.I` зҡ„еҖј 4 в”ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Ө в”Ӯ 0x4A984D88 в”Ӯ -- `refType.S` зҡ„е Ҷең°еқҖ 8 в”ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Ө в”Ӯ 0x89ABCDEF в”Ӯ -- `refType.L` зҡ„дҪҺ32дҪҚ в”Ӯ 0x01234567 в”Ӯ -- `refType.L` зҡ„й«ҳ32дҪҚ 16 в””в”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”ҳ
ең°еқҖдёә0x4AA4C288пјҲеҚіintArrayзҡ„еҖјпјүзҡ„еҶ…еӯҳдјҡеғҸиҝҷж ·:
0 в”Ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”җ в”Ӯ 4 в”Ӯ -- ж•°з»„й•ҝеәҰ 4 в”ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Ө в”Ӯ 300 в”Ӯ -- `intArray [0]` 8 в”ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Ө в”Ӯ 301 в”Ӯ -- `intArray [1]` 12 в”ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Ө в”Ӯ 302 в”Ӯ -- `intArray [2]` 16 в”ңв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Ө в”Ӯ 303 в”Ӯ -- `intArray [3]` 20 в””в”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”Җв”ҳ
зҺ°еңЁпјҢеҰӮжһңе°ҶintArrayдј йҖ’з»ҷеҸҰдёҖдёӘеҮҪж•°пјҢеҲҷжҺЁйҖҒеҲ°е Ҷж ҲдёҠзҡ„еҖје°ҶжҳҜ0x4AA4C288пјҢеҚіж•°з»„зҡ„ең°еқҖпјҢиҖҢдёҚжҳҜж•°з»„зҡ„еүҜжң¬гҖӮ
- P Daddy
8
61我注意到“所有局部变量都存储在栈上”的说法是不准确的。匿名函数的外部变量和迭代器块、异步块的局部变量都存储在堆上。被寄存器化的局部变量既不存储在栈上也不存储在堆上。省略的局部变量也不存储在栈上也不存储在堆上。 - Eric Lippert
5LOL,Lippert 先生总是吹毛求疵。 :) 我觉得有必要指出,在您后两个例子之外,所谓的“本地变量”在编译时就不再是本地变量了。实现将它们提升为类成员的身份,这也是它们被存储在堆上的唯一原因。因此,这只是一个实现细节(咯咯笑)。当然,寄存器存储是更低级别的实现细节,而省略不算。 - P Daddy
4当然,我的整篇文章都是实现细节,但正如您所了解的那样,这一切都是为了区分“变量”和“值”的概念。 变量(可以称之为本地变量、字段、参数等)可以存储在堆栈、堆或其他一些实现定义的地方,但这并不是真正重要的。 重要的是该变量是直接存储表示其值的值,还是仅存储对该值的引用,该值存储在其他地方。 这很重要,因为它会影响复制语义:复制该变量是复制其值还是其地址。 - P Daddy
20显然,你对“本地变量”的定义与我不同。你似乎认为“本地变量”是由其实现细节所特征的。在我所知道的C#规范中,并没有任何依据证明这种观点的正确性。实际上,“本地变量”是指在块内声明的变量,其名称仅在与该块关联的声明空间内作用域。我向你保证,即使将作为实现细节提升到闭包类字段的本地变量,仍然符合C#规则下的本地变量。 - Eric Lippert
21话虽如此,您的回答通常非常优秀;强调“价值观”在概念上与“变量”不同是一个非常基础的点,需要尽可能频繁地强调,但很多人仍然相信一些奇怪的神话!因此,您为维护正确的观点而战斗是值得赞扬的。 - Eric Lippert
显示剩余3条评论
25
是的,数组将位于堆上。
数组内部的整数不会被装箱。仅仅因为值类型存在于堆上,并不一定意味着它将被装箱。当一个值类型,比如 int,被分配给类型为 object 的引用时才会发生装箱。例如:
以下代码不会装箱:
int i = 42;
myIntegers[0] = 42;
盒子:
object i = 42;
object[] arr = new object[10]; // no boxing here
arr[0] = 42;
您可能还想查看Eric在这个主题上的帖子:
- JaredPar
8
1但我不明白。值类型不应该在堆栈上分配吗?或者值类型和引用类型都可以在堆栈或堆上分配,只是它们通常只存储在一个地方而已? - devoured elysium
6如果一个值类型没有引用类型的包装器/容器,那么它将存储在堆栈中。但是一旦它被放置在引用类型的容器中使用,它就会存在于堆中。数组是引用类型,因此 int 的内存必须存在于堆中。 - JaredPar
2@Jorge:引用类型仅存在于堆中,从不在栈中。相反,在可验证的代码中,无法将指向栈位置的指针存储到引用类型的对象中。 - Anton Tykhyy
1我觉得你的意思是将 i 赋值给 arr[0]。常量赋值仍然会导致"42"的装箱,但既然你已经创建了 i,那么还是使用它吧;-) - Marcus Griep
@JaredPar 您在这里的回答非常关键,因为整个想法在我的脑海中是清晰的,除了 int[] 是值类型,为什么它在堆上,您给出了答案,谢谢。 - Murat Can OĞUZHAN
显示剩余3条评论
25
为了理解发生的情况,以下是一些事实:
如果你有一个字符串数组,它实际上是一个字符串引用的数组。由于引用是值类型,它们将成为堆上数组对象的一部分。如果你把一个字符串对象放入数组中,你实际上是把对字符串对象的引用放入数组中,而字符串是一个单独的对象在堆上存在。
- 对象总是在堆上分配。
- 堆只包含对象。
- 值类型要么被分配在栈上,要么作为堆上对象的一部分。
- 数组是一个对象。
- 数组只能包含值类型。
- 对象引用是值类型。
如果你有一个字符串数组,它实际上是一个字符串引用的数组。由于引用是值类型,它们将成为堆上数组对象的一部分。如果你把一个字符串对象放入数组中,你实际上是把对字符串对象的引用放入数组中,而字符串是一个单独的对象在堆上存在。
- Guffa
4
是的,引用类型的行为就像值类型一样,但我注意到它们通常不被称为值类型,也不包括在值类型中。例如,请参见(但类似于此类的还有很多)http://msdn.microsoft.com/en-us/library/s1ax56ch.aspx - H H
@Henk:是的,你说得对,参考并没有列在值类型变量中,但就它们的内存分配方式而言,它们在所有方面都是值类型,理解这一点非常有用,可以帮助我们更好地了解内存分配的整个过程。 :) - Guffa
1我对第五点“数组只能包含值类型”表示怀疑。
那字符串数组呢?
string[] strings = new string[4]; - Sunil Purushothaman
如果你有一个字符串数组,它实际上是一个字符串引用的数组。但对于int[],它只保留了in[]的引用,我说得对吗? - Murat Can OĞUZHAN
12
我认为你的问题的核心在于对引用类型和值类型的理解上存在误解。这是可能每个.NET和Java开发人员都会遇到的问题。
数组只是一组值,如果它是一个引用类型的数组(比如string[]),那么数组是一个指向堆上各种string对象的引用列表,因为引用就是引用类型的值。在内部,这些引用被实现为指向内存地址的指针。如果你想可视化这一点,在内存中(在堆上)这样一个数组看起来像这样:
[ 00000000,00000000,00000000,F8AB56AA ]
这是一个包含4个引用到堆上string对象的string数组(这里的数字是十六进制)。目前,只有最后一个string实际指向任何东西(内存在分配时初始化为全0),这个数组基本上是C#中此代码的结果:
string[] strings = new string[4];
strings[3] = "something"; // the string was allocated at 0xF8AB56AA by the CLR
在一个 32 位程序中,上述数组将以这种方式呈现。在一个 64 位程序中,引用会变得两倍大(F8AB56AA 将变成 00000000F8AB56AA)。
如果您有一个值类型的数组(比如一个 int[]),那么该数组是一个整数列表,因为值类型的 值 本身就是它的值(因此被称为值类型)。这样一个数组的可视化如下:
[ 00000000, 45FF32BB, 00000000, 00000000 ]
这是一个由 4 个整数组成的数组,其中只有第二个整数被赋了一个值(为1174352571,即该十六进制数的十进制表示),而其余的整数为0(正如我所说,内存被初始化为零,而十六进制的00000000在十进制中表示为0)。生成该数组的代码如下:
int[] integers = new int[4];
integers[1] = 1174352571; // integers[1] = 0x45FF32BB would be valid too
这个 int[] 数组也会被存储在堆内存中。
举另一个例子,一个short[4]数组的内存会长成这样:
[ 0000, 0000, 0000, 0000 ]
因为short的值是2字节的数字。
值类型存储的位置只是实现细节,正如Eric Lippert在这里非常好地解释的那样,并不与值类型和引用类型之间的区别(即行为差异)本质相关。
当你将某些内容传递给方法(无论是引用类型还是值类型),实际上传递给方法的是该类型的值的一个副本。对于引用类型,值是一个引用(请将其视为指向某个内存位置的指针,尽管这也是一种实现细节),而对于值类型,该值就是它本身。
// Calling this method creates a copy of the *reference* to the string
// and a copy of the int itself, so copies of the *values*
void SomeMethod(string s, int i){}
只有在将值类型转换为引用类型时才会发生装箱。这段代码会发生装箱:
object o = 5;
- JulianR
1
我相信“实现细节”应该是一个字体大小为50像素的。 ;) - sisve
4
这些插图展示了@P Daddy上面的回答。
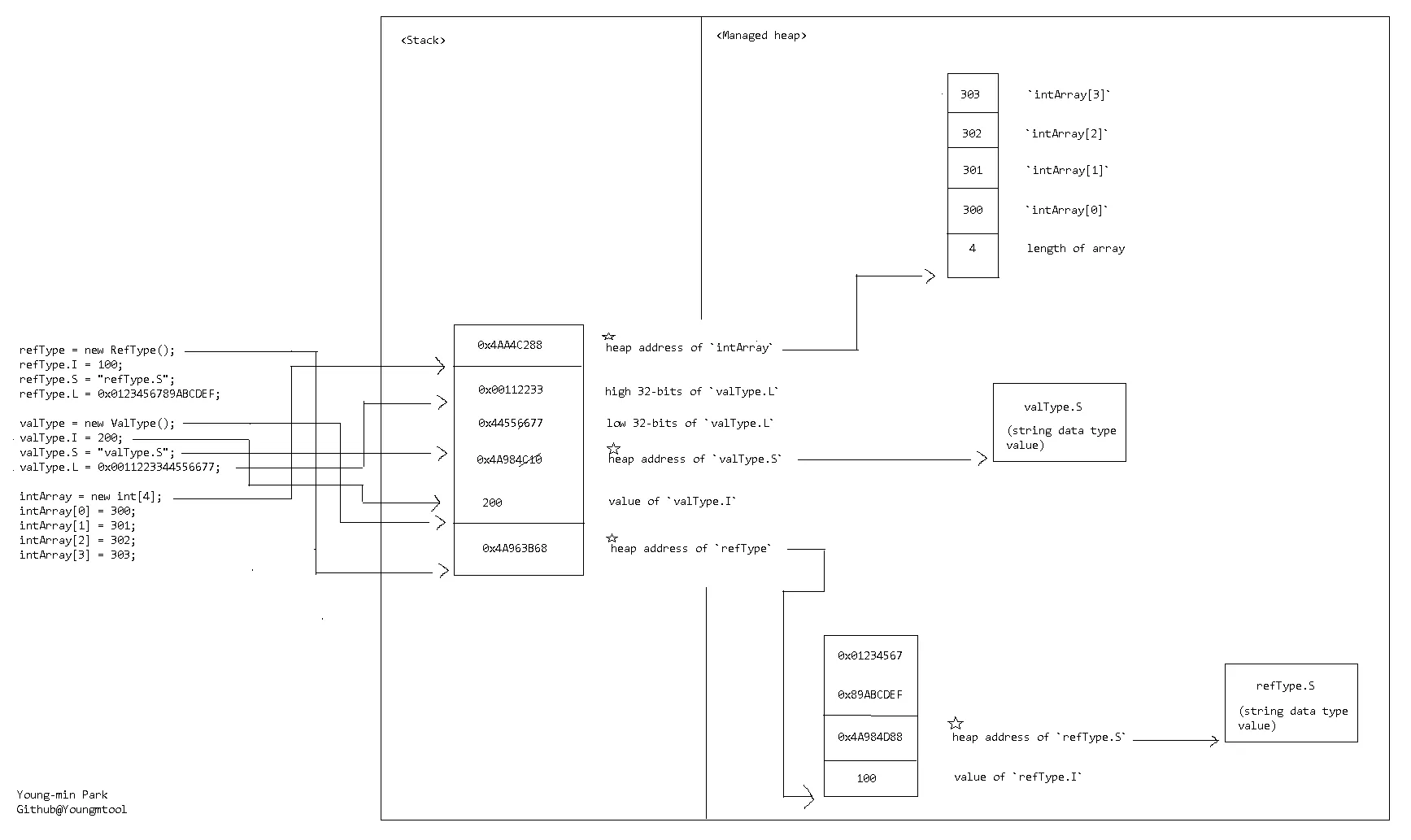
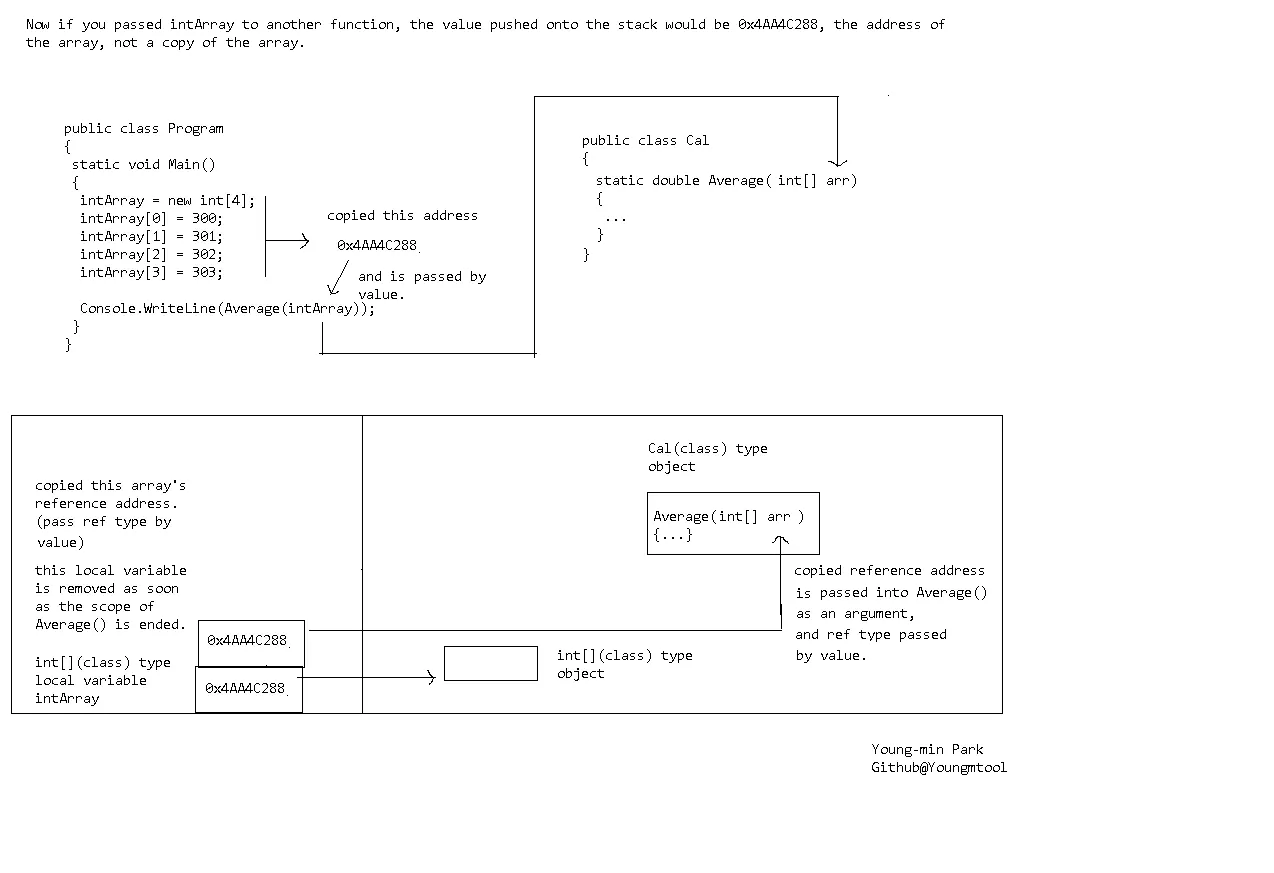
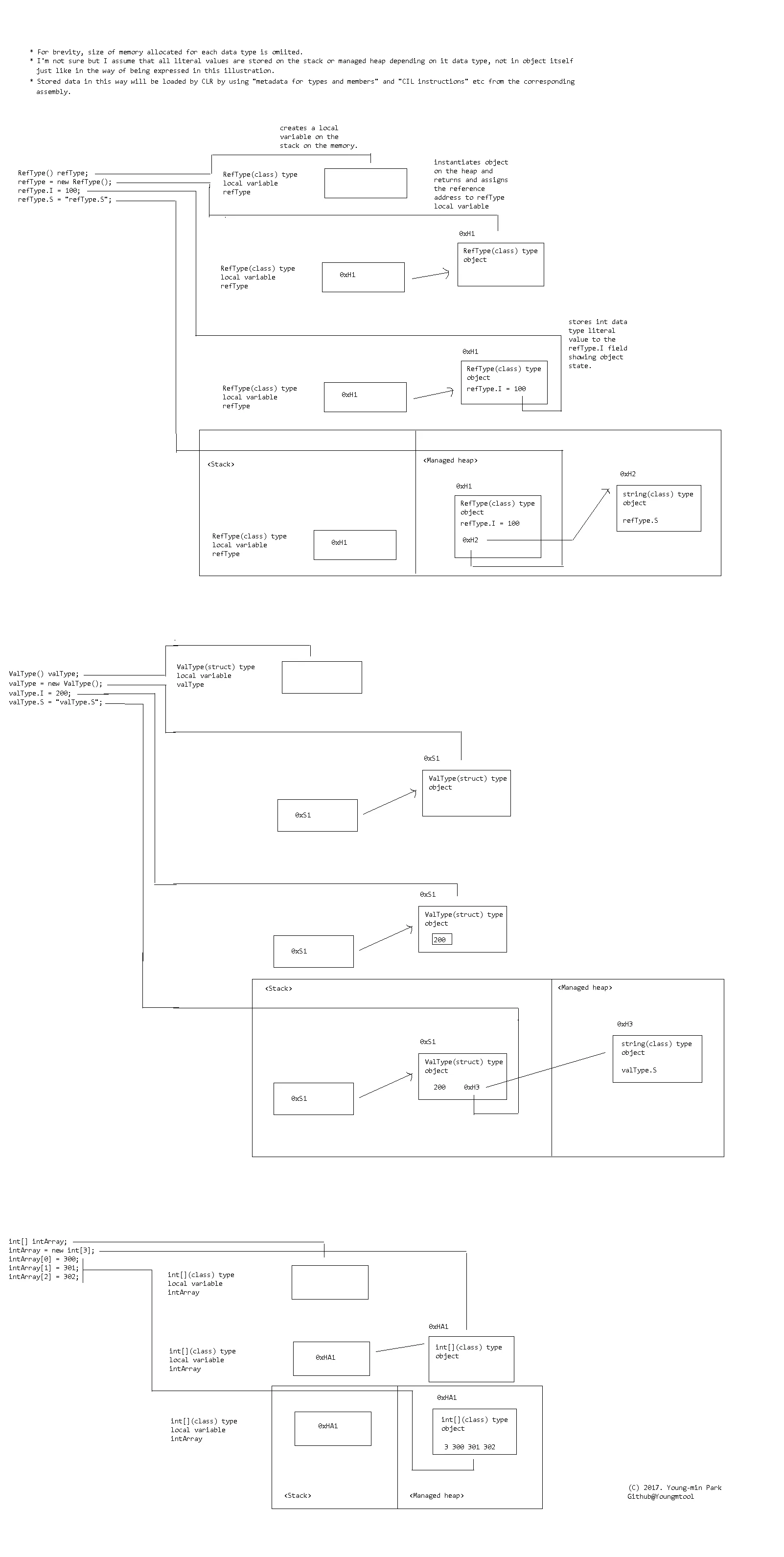
- YoungMin Park
3
@P Daddy,我画了一些插图,请检查是否有错误部分。另外我还有一些问题。
- 当我创建一个长度为4的int类型数组时,长度信息(4)也会一直存储在内存中吗?
- 在第二个示例中,复制的数组地址存储在哪里? 它是否与intArray地址存储在同一堆栈区域中? 是其他堆栈但相同类型的堆栈吗? 还是不同类型的堆栈?
- 低32位/高32位是什么意思?
- 当我使用new关键字在堆栈上分配值类型(在此示例中为结构)时,返回值是什么?它也是地址吗? 当我通过这个语句Console.WriteLine(valType)进行检查时,它会显示完全限定名称,就像对象ConsoleApp.ValType一样。
- valType.I=200;
3
每个人都说得足够多了,但如果有人正在寻找有关堆、栈、局部变量和静态变量的清晰(但非官方)示例和文档,请参考Jon Skeet完整的文章.NET中的内存-放置在哪里。
< p > < em > < strong > 摘录:
每个本地变量(即在方法中声明的变量)都存储在堆栈上。这包括引用类型变量 - 变量本身在堆栈上,但请记住,引用类型变量的值仅是引用(或null),而不是对象本身。方法参数也算作本地变量,但如果它们使用ref修饰符声明,则它们不会获得自己的插槽,而是与调用代码中使用的变量共享插槽。有关更多详细信息,请参阅我的有关参数传递的文章。
引用类型的实例变量始终位于堆上。这就是对象本身所在的位置。
值类型的实例变量存储在声明值类型的变量的上下文中。实例的内存插槽有效地包含实例中每个字段的插槽。这意味着(考虑到前两点),在方法中声明的结构体变量始终位于堆栈上,而作为类的实例字段的结构体变量将位于堆上。
每个静态变量都存储在堆上,无论它是在引用类型还是值类型中声明的。总共只有一个插槽,无论创建了多少个实例。(虽然不需要创建任何实例来存在该插槽。)这些变量生活在哪个堆上的详细信息很复杂,但在MSDN文章中有详细解释。
引用类型的实例变量始终位于堆上。这就是对象本身所在的位置。
值类型的实例变量存储在声明值类型的变量的上下文中。实例的内存插槽有效地包含实例中每个字段的插槽。这意味着(考虑到前两点),在方法中声明的结构体变量始终位于堆栈上,而作为类的实例字段的结构体变量将位于堆上。
每个静态变量都存储在堆上,无论它是在引用类型还是值类型中声明的。总共只有一个插槽,无论创建了多少个实例。(虽然不需要创建任何实例来存在该插槽。)这些变量生活在哪个堆上的详细信息很复杂,但在MSDN文章中有详细解释。
- gmaran23
2
你的“什么放在哪里”的链接已经失效了。 - Jabba
我目前无法编辑它,Skeet的正确文章链接是:https://jonskeet.uk/csharp/memory.html - Kale_Surfer_Dude
1
你的示例代码中没有装箱。
值类型可以像 int 数组一样存在于堆上。该数组在堆上分配并存储 int,这些 int 恰好是值类型。数组的内容被初始化为 default(int),这恰好是零。
考虑一个包含值类型的类:
class HasAnInt
{
int i;
}
HasAnInt h = new HasAnInt();
变量'h'是指在堆上存在的HasAnInt实例。它恰好包含一个值类型。这完全没问题,因为'i'作为类中的一部分也恰好存储在堆上。在这个示例中没有装箱操作。
- Curt Nichols
1
在堆上分配了一个整数数组,仅此而已。myIntegers 引用了分配整数的部分的开头。该引用位于堆栈上。
如果您有一组引用类型对象的数组,例如 Object 类型,myObjects[] 位于堆栈上,将引用一堆值,这些值引用了对象本身。
总之,如果您将 myIntegers 传递给某些函数,则只传递对实际整数堆的引用。
- Dykam
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 11 C++中谁负责堆和栈?
- 3 类数组。使用堆还是栈?
- 6 堆/栈和多进程
- 3 全局数组分配 — 栈还是堆?
- 17 为什么需要堆和栈?
- 7 对象类 基本类型 栈和堆
- 10 一个栈和栈,以及一个堆和堆的区别
- 6 JVM - 堆和栈
- 10 Windows汇编堆和栈?
- 7 线程堆和栈