注意:我可以控制数据文件的格式,但它必须是单个文件。
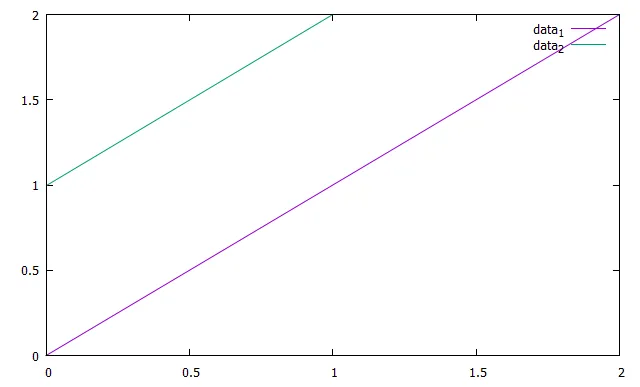
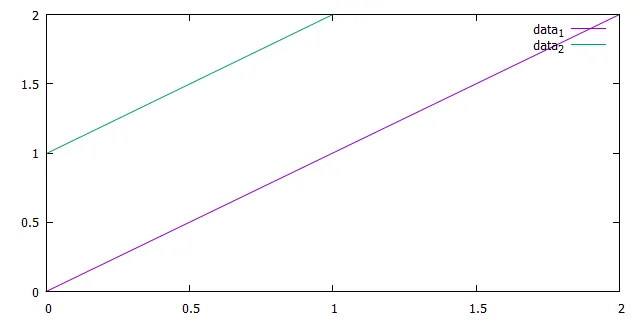
我试图使用gnuplot在同一张图上绘制多个数据集。我想理想情况下绘制如下图所示的内容:
在这种情况下,
我还想避免在 gnuplot 脚本中放置可能数据集的列表或数量。基本上,我希望通过特定字段“分组”数据点,并将每个组作为单独的数据集绘制在同一图表上。
作为最后的备选方案,我可以使用 grep 将原始文件拆分为每个数据集一个文件,并绘制它们(我想这更容易?),但我正在寻找一种使用单个文件来完成它的方法。
我试图使用gnuplot在同一张图上绘制多个数据集。我想理想情况下绘制如下图所示的内容:
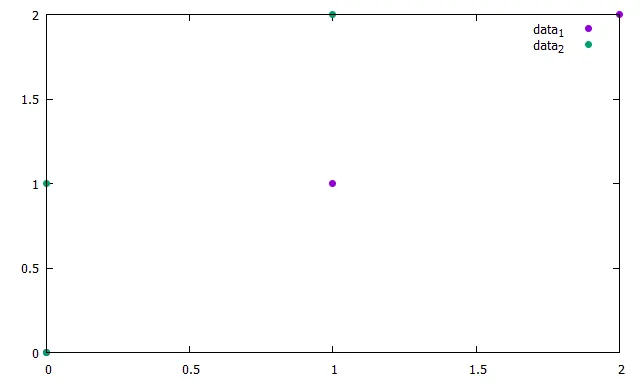
data_1 0 0
data_2 0 0
data_1 1 1
data_2 0 1
data_1 2 2
data_2 1 2
在这种情况下,
data_1 和 data_2 应该是两个单独的曲线。我还想避免在 gnuplot 脚本中放置可能数据集的列表或数量。基本上,我希望通过特定字段“分组”数据点,并将每个组作为单独的数据集绘制在同一图表上。
作为最后的备选方案,我可以使用 grep 将原始文件拆分为每个数据集一个文件,并绘制它们(我想这更容易?),但我正在寻找一种使用单个文件来完成它的方法。