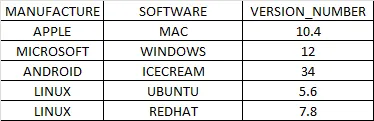
也许标题并不是我能用来描述问题的最佳选择。我正在处理的表结构示例如下图所示。我需要编写一个查询来提取所有“制造商”拥有多个记录的记录。因此,最终结果将是LINUX UBUNTU 5.6和LINUX REDHAT 7.8。
只返回重复的“制造商”很容易,我可以使用分组计数(*)>1来做到这一点,但是当涉及到返回重复的制造商和相应的列时,我遇到了问题。
只返回重复的“制造商”很容易,我可以使用分组计数(*)>1来做到这一点,但是当涉及到返回重复的制造商和相应的列时,我遇到了问题。
返回重复的生产商很容易,使用分组
having count(*) > 1即可。
很好的开端。现在使用那个manufacture列表来选择剩余的数据:
SELECT *
FROM software
WHERE manufacture IN (
-- This is your "HAVING COUNT(*) > 1" query inside.
-- It drives the selection of rows in the outer query.
SELECT manufacture
FROM software
GROUP BY manufacture
HAVING COUNT(*) > 1
)
Select * from myTable
Where Manufacture In
(Select Manufacture
from myTable
Group By Manufacture
Having count(*) > 1)
你尝试过类似这样的东西吗:
select p.manufacture, p.product, p.version
from (select manufacture, count(*)
from products
group by manufacture) as my_count
inner join products as p on p.manufacture = my_count.manufacture
where my_count > 1