我正在使用C#和Sql Server 2008开发ASP.NET项目。
我有三张表:

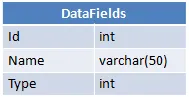
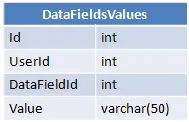
每个用户都有一个特定的数据字段值,并且这个值存储在DataFieldsValues中。
现在我想要展示像这样的报告:

我创建了User和DataField对象。在DataField对象中,有方法string GetValue(User user),用于获取某个用户的某个字段的值。
然后我有List<User> users和List<DataField> fields列表,我做如下操作:
string html = string.Empty;
html += "<table>";
html += "<tr><th>Username</th>";
foreach (DataField f in fields)
{
html += "<th>" + f.Name + "</th>";
}
html += "</tr>"
foreach (User u in users)
{
html += "<tr><td>" + u.Username + "</td>"
foreach (DataField f in fields)
{
html += "<td>" + f.GetValue(u) + "</td>";
}
html += "</tr>"
}
Response.Write(html);
这个方法可以正常工作,但是非常缓慢,我指的是20个用户和10个数据字段。在性能方面有没有更好的方法来实现这个功能?
编辑:对于类中的每个参数,我使用以下方法检索值:
public static string GetDataFromDB(string query)
{
string return_value = string.Empty;
SqlConnection sql_conn;
sql_conn = new SqlConnection(ConfigurationManager.ConnectionStrings["XXXX"].ToString());
sql_conn.Open();
SqlCommand com = new SqlCommand(query, sql_conn);
//if (com.ExecuteScalar() != null)
try
{
return_value = com.ExecuteScalar().ToString();
}
catch (Exception x)
{
}
sql_conn.Close();
return return_value;
}
例如:
public User(int _Id)
{
this.Id = _Id
this.Username = DBAccess.GetDataFromDB("select Username from Users where Id=" + this.Id)
//...
}
StringBuilder替代字符串来做一件事情。 - Suraj Singh