在我继续进行操作系统开发研究的努力中,我已经在脑海中构建了一个几乎完整的图景。但有一件事仍让我困惑。
以下是基本的启动过程,据我所知:
1) BIOS/引导加载程序执行必要的检查,初始化所有内容。
2) 将内核加载到RAM中。
3) 内核执行其初始化并开始调度任务。
4) 当加载任务时,它被赋予一个虚拟地址空间,包括.text、.data、.bss、堆和栈。该任务“维护”其自己的堆栈指针,指向其自己的“虚拟”堆栈。
5) 上下文切换只需将寄存器文件(所有CPU寄存器)、堆栈指针和程序计数器推入某个内核数据结构,并加载另一个属于另一个进程的集合。
在这种抽象中,内核是一个“母”进程,在其中托管所有其他进程。我尝试在以下图表中传达我最好的理解:
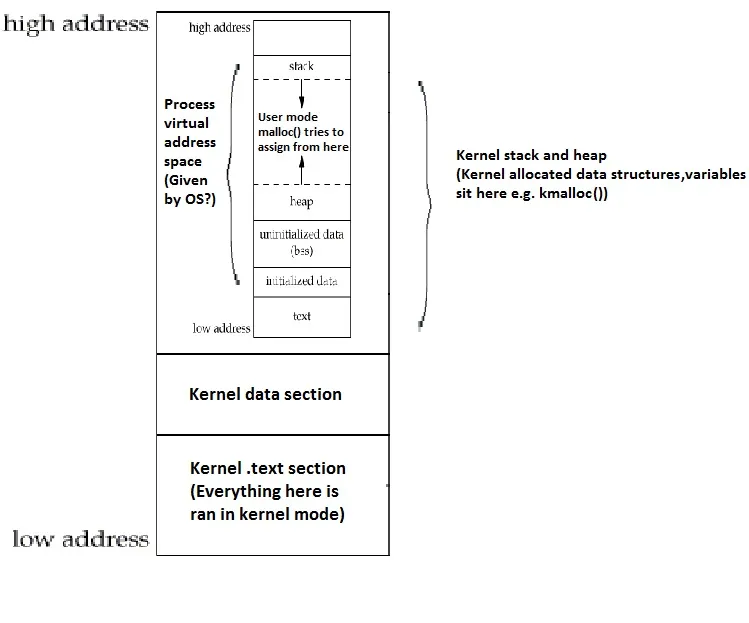
问题是,首先这个简单模型正确吗?
其次,可执行程序如何知道它的虚拟堆栈呢?它是操作系统的工作来计算虚拟堆栈指针并将其放置在相关CPU寄存器中吗?剩余的堆栈簿记由CPU推和弹出命令完成吗?
内核本身有自己的主堆栈和堆吗?
谢谢。
kthread)都是线程。此外,一个用户模式线程实际上会有多个堆栈:一个在用户模式下,另一个在内核中。 - Jonathon Reinhart