我有一个非常简单的问题,但当我试图找出哪个解决方案更快时,却得到了一些奇怪的结果。
原始问题:给定两个列表ListA、ListB和一个常量k,删除所有两个列表之和为k的条目。
我用两种方法解决了这个问题:首先我尝试使用循环,然后我使用列表推导式和zip()来压缩和解压缩两个列表。
使用循环的版本。
导入语句:
创建图表的代码:
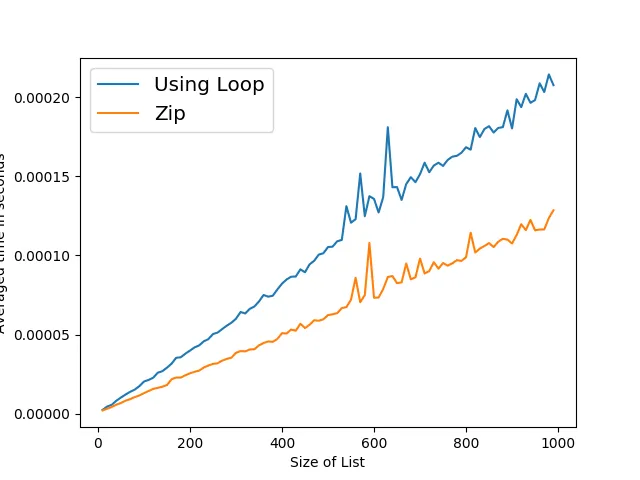
当我使用新的装饰器时,使用for循环的版本不受影响,但使用
更新-更新-更新:
这与垃圾收集器有关,因为如果我使用
原始问题:给定两个列表ListA、ListB和一个常量k,删除所有两个列表之和为k的条目。
我用两种方法解决了这个问题:首先我尝试使用循环,然后我使用列表推导式和zip()来压缩和解压缩两个列表。
使用循环的版本。
def Remove_entries_simple(listA, listB, k):
""" removes entries that sum to k """
new_listA = []
new_listB = []
for index in range(len(listA)):
if listA[index] + listB[index] == k:
pass
else:
new_listA.append(listA[index])
new_listB.append(listB[index])
return(new_listA, new_listB)
使用列表推导和zip()函数的版本
def Remove_entries_zip(listA, listB, k):
""" removes entries that sum to k using zip"""
zip_lists = [(a, b) for (a, b) in zip(listA, listB) if not (a+b) == k]
# unzip the lists
new_listA, new_listB = zip(*zip_lists)
return(list(new_listA), list(new_listB))
然后我尝试确定哪种方法更快。但是我得到了下面图表所示的结果(x轴:列表大小,y轴:运行它的平均时间,10 ** 3次重复)。由于某种原因,使用zip()版本总是在大约相同的位置跳跃 - 我在不同的机器上多次运行它。有人能解释一下可能导致这种奇怪行为的原因吗?
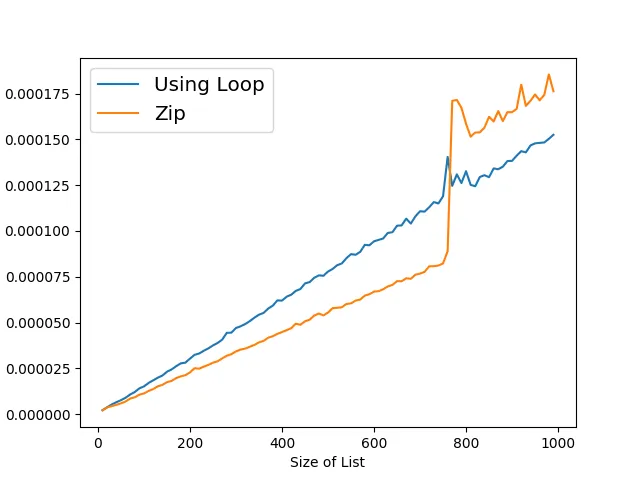
导入语句:
import random
import time
import matplotlib.pyplot as plt
函数装饰器:
def Repetition_Decorator(fun, Rep=10**2):
''' returns the average over Rep repetitions'''
def Return_function(*args, **kwargs):
Start_time = time.clock()
for _ in range(Rep):
fun(*args, **kwargs)
return (time.clock() - Start_time)/Rep
return Return_function
创建图表的代码:
Zippedizip = []
Loops = []
The_Number = 10
Size_list = list(range(10, 1000, 10))
Repeated_remove_loop = Repetition_Decorator(Remove_entries_simple, Rep=10**3)
Repeated_remove_zip = Repetition_Decorator(Remove_entries_zip, Rep=10**3)
for size in Size_list:
ListA = [random.choice(range(10)) for _ in range(size)]
ListB = [random.choice(range(10)) for _ in range(size)]
Loops.append(Repeated_remove_loop(ListA, ListB, The_Number))
Zippedizip.append(Repeated_remove_zip(ListA, ListB, The_Number))
plt.xlabel('Size of List')
plt.ylabel('Averaged time in seconds')
plt.plot(Size_list, Loops, label="Using Loop")
plt.plot(Size_list, Zippedizip, label="Zip")
plt.legend(loc='upper left', shadow=False, fontsize='x-large')
plt.show()
更新-更新:感谢kaya3指出timeit模块。
为了尽可能接近我的原始代码,同时使用timeit模块,我创建了一个新的函数装饰器来计时代码。
新的装饰器:
def Repetition_Decorator_timeit(fun, Rep=10**2):
"""returns average over Rep repetitions with timeit"""
def Return_function(*args, **kwargs):
partial_fun = lambda: fun(*args, **kwargs)
return timeit.timeit(partial_fun, number=Rep) / Rep
return Return_function
当我使用新的装饰器时,使用for循环的版本不受影响,但使用
zip的版本不再跳跃。
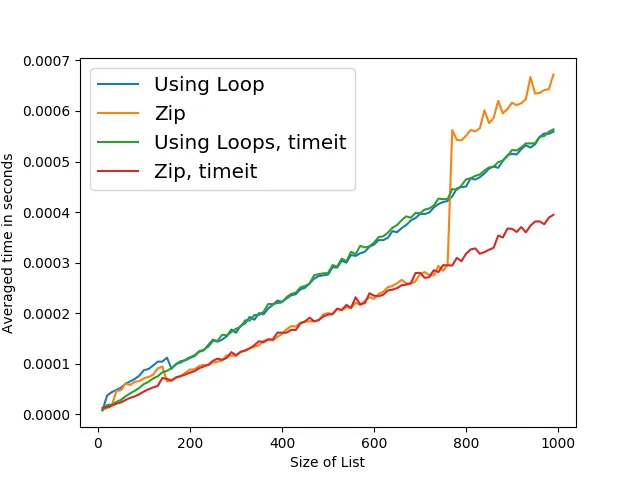
更新-更新-更新:
这与垃圾收集器有关,因为如果我使用
gc.disable() 禁用垃圾收集器,则两种测量方法都会给出相同的结果。
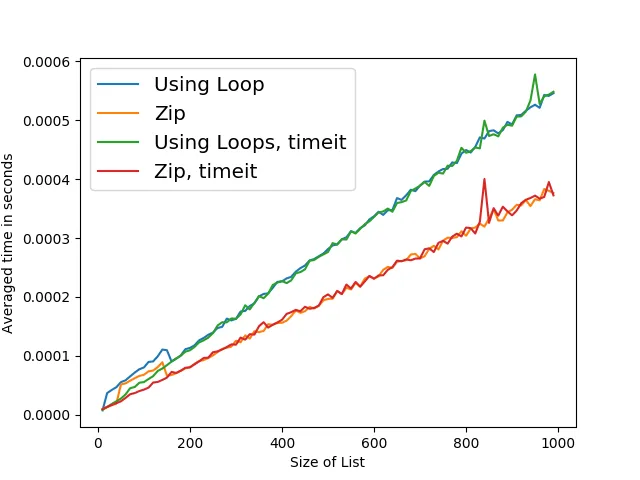
timeit模块来测量代码片段的性能。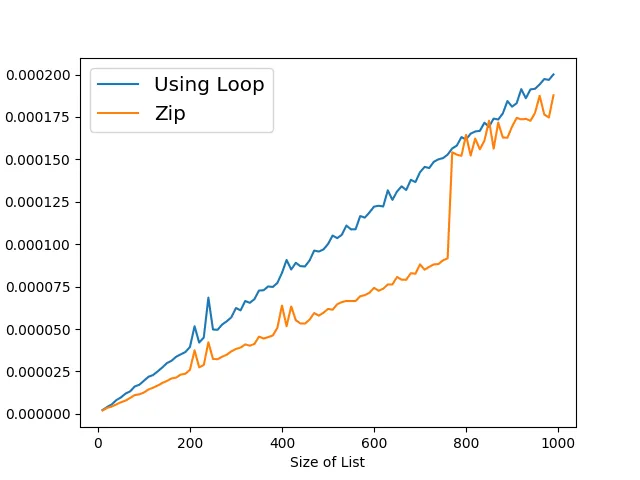
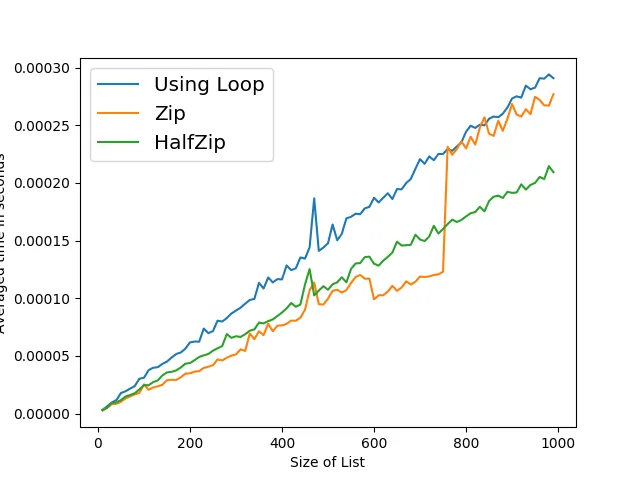
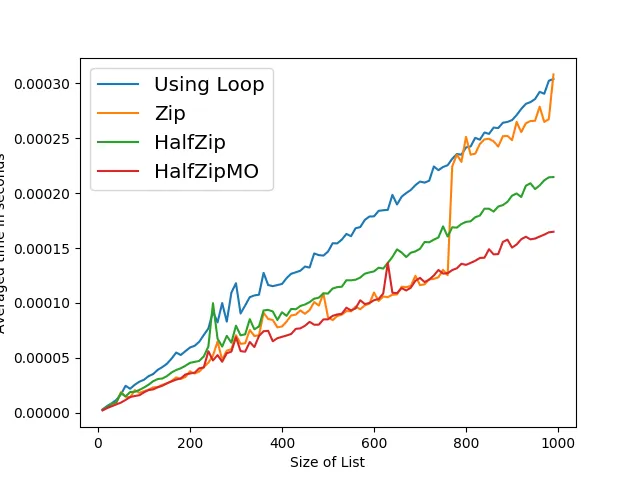
zip的版本在大小从100到10,000的情况下始终快约30%。 - kaya3