我写了一个小程序来完成以下任务。我想知道是否有更优的解决方案:
1)获取两个字符串列表。一般情况下,第二个列表中的字符串比第一个列表中的长,但不能保证。
2)返回从第二个列表派生的字符串列表,该列表已删除第一个列表中的任何匹配字符串。因此,该列表将包含<=第二个列表中字符串长度的字符串。
下面是我所说的内容的图片示例: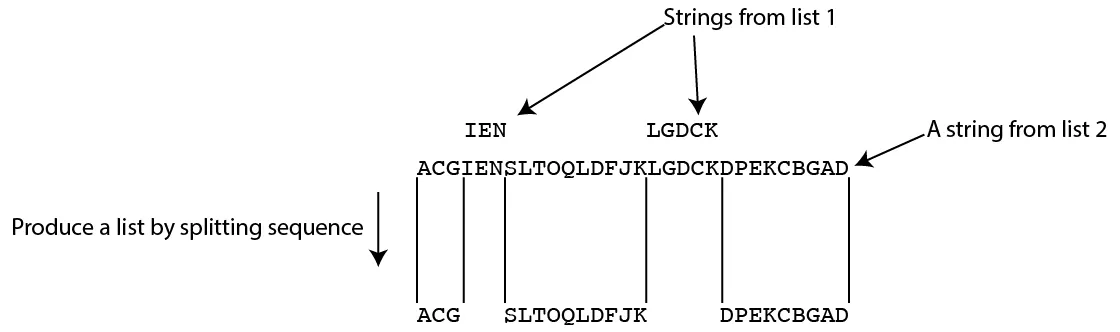 到目前为止,我有这个。它似乎正常工作,但我只是好奇是否有更优雅的解决方案。顺便说一下,我正在跟踪每个字符串的开始和结束的“位置”,这对于程序的后续部分很重要。
到目前为止,我有这个。它似乎正常工作,但我只是好奇是否有更优雅的解决方案。顺便说一下,我正在跟踪每个字符串的开始和结束的“位置”,这对于程序的后续部分很重要。
1)获取两个字符串列表。一般情况下,第二个列表中的字符串比第一个列表中的长,但不能保证。
2)返回从第二个列表派生的字符串列表,该列表已删除第一个列表中的任何匹配字符串。因此,该列表将包含<=第二个列表中字符串长度的字符串。
下面是我所说的内容的图片示例:
到目前为止,我有这个。它似乎正常工作,但我只是好奇是否有更优雅的解决方案。顺便说一下,我正在跟踪每个字符串的开始和结束的“位置”,这对于程序的后续部分很重要。def split_sequence(sequence = "", split_seq = "", length = 8):
if len(sequence) < len(split_seq):
return [],[]
split_positions = [0]
for pos in range(len(sequence)-len(split_seq)):
if sequence[pos:pos+len(split_seq)] == split_seq and pos > split_positions[-1]:
split_positions += [pos, pos+len(split_seq)]
if split_positions[-1] == 0:
return [sequence], [(0,len(sequence)-1)]
split_positions.append(len(sequence))
assert len(split_positions) % 2 == 0
split_sequences = [sequence[split_positions[_]:split_positions[_+1]] for _ in range(0, len(split_positions),2)]
split_seq_positions = [(split_positions[_],split_positions[_+1]) for _ in range(0, len(split_positions),2)]
return_sequences = []
return_positions = []
for pos,seq in enumerate(split_sequences):
if len(seq) >= length:
return_sequences.append(split_sequences[pos])
return_positions.append(split_seq_positions[pos])
return return_sequences, return_positions
def create_sequences_from_targets(sequence_list = [] , positions_list = [],length=8, avoid = []):
if avoid:
for avoided_seq in avoid:
new_sequence_list = []
new_positions_list = []
for pos,sequence in enumerate(sequence_list):
start = positions_list[pos][0]
seqs, positions = split_sequence(sequence = sequence, split_seq = avoided_seq, length = length)
new_sequence_list += seqs
new_positions_list += [(positions[_][0]+start,positions[_][1]+start) for _ in range(len(positions))]
return new_sequence_list, new_positions_list
一个样本输出:
In [60]: create_sequences_from_targets(sequence_list=['MPHSSLHPSIPCPRGHGAQKA', 'AEELRHIHSRYRGSYWRTVRA', 'KGLAPAEISAVCEKGNFNVA'],positions_list=[(0, 20), (66, 86), (136, 155)],avoid=['SRYRGSYW'],length=3)
Out[60]:
(['MPHSSLHPSIPCPRGHGAQKA', 'AEELRHIH', 'RTVRA', 'KGLAPAEISAVCEKGNFNVA'],
[(0, 20), (66, 74), (82, 87), (136, 155)])
string.split()接受一个子字符串分隔符。你的算法看起来可以简单地遍历分隔符字符串。 - Brian Cain