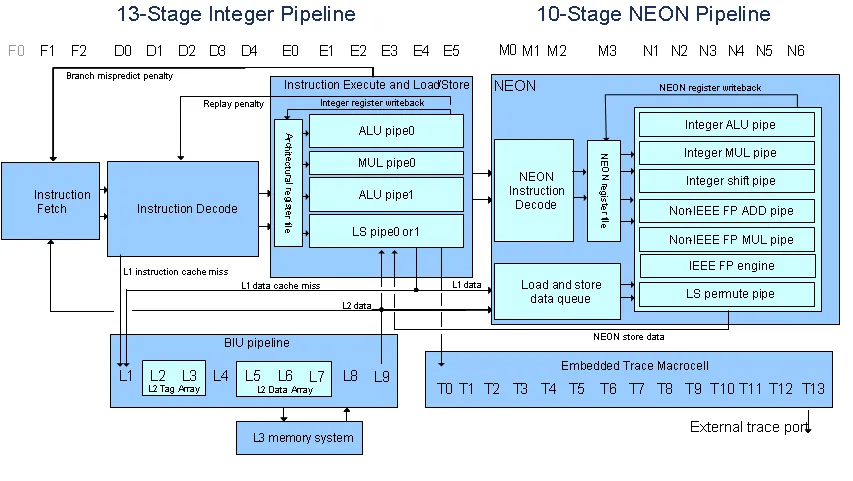
可能看起来类似于:ARM和NEON可以同时工作吗?,但它不是,我有一些其他问题(可能是我的理解问题):
在协议栈中,当我们计算校验和时,这是在GPP上完成的,现在我将其作为函数的一部分交给了NEON:
这是我作为NEON的一部分编写的校验和函数,发布在Stack Overflow上:Neon纹理内核的校验码实现 现在,假设从Linux调用此函数。
正如您所看到的,do_csum被调用,我们正在等待该结果(或者看起来是这样)。
注意:
1. 从cortex-a8的角度来说 2. 如您从链接中所见,do_csum使用内部函数编码 3. 使用GNU工具链进行编译 4. 如果您还涉及到多线程或其他涉及这些交互操作的概念,则会很好。
问题:
1. 在NEON执行其操作时,ARM是否闲置?(在这种特定情况下) 2. 或者,它搁置了与当前ip_csum相关的代码,并采取另一个进程/线程,直到NEON完成为止?(对于我而言,我对此发生的情况几乎一无所知) 3. 如果它正在闲置,我们如何让ARM在NEON完成之前处理其他事情?
在协议栈中,当我们计算校验和时,这是在GPP上完成的,现在我将其作为函数的一部分交给了NEON:
这是我作为NEON的一部分编写的校验和函数,发布在Stack Overflow上:Neon纹理内核的校验码实现 现在,假设从Linux调用此函数。
ip_csum(){
…
…
csum = do_csum(); //function call from arm
…
…
}
do_csum(){
…
…
//NEON optimised code
…
…
returns the final checksum to ip_csum/linux/ARM
}
正如您所看到的,do_csum被调用,我们正在等待该结果(或者看起来是这样)。
注意:
1. 从cortex-a8的角度来说 2. 如您从链接中所见,do_csum使用内部函数编码 3. 使用GNU工具链进行编译 4. 如果您还涉及到多线程或其他涉及这些交互操作的概念,则会很好。
问题:
1. 在NEON执行其操作时,ARM是否闲置?(在这种特定情况下) 2. 或者,它搁置了与当前ip_csum相关的代码,并采取另一个进程/线程,直到NEON完成为止?(对于我而言,我对此发生的情况几乎一无所知) 3. 如果它正在闲置,我们如何让ARM在NEON完成之前处理其他事情?