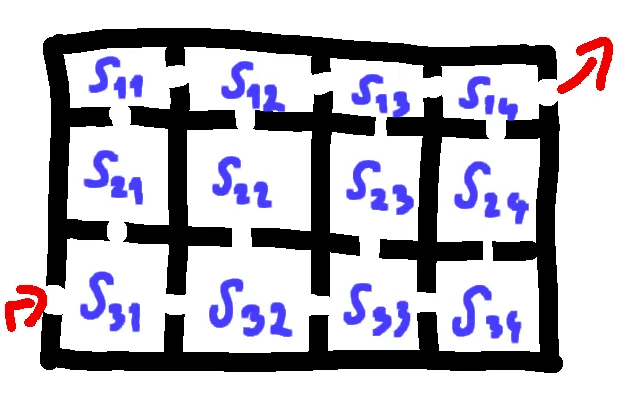
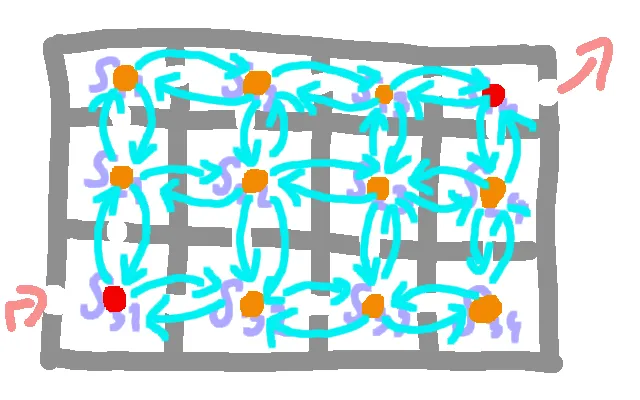
我在将贝尔曼-福德算法应用于二维数组(而不是图形)时遇到了问题。
输入数组具有 m x n 的尺寸:
s[1,1] s[1,2] ... s[1,n] -> Exit
s[2,1] s[2,2] ... s[2,n]
...
Entry -> s[m,1] s[m,2] ... s[m,n]
并且它是类似于房间的(每个入口都是一个具有s[x,y]进入成本的房间)。每个房间也可以有一个负成本,我们必须找到从入口到选择的房间和出口的最便宜的路径。
例如,我们有这样一个包含房间和成本的数组:
1 5 6
2 -3 4
5 2 -8
我们希望走过房间[3,2],s[3,2] = 4。我们从[1,3]的5开始,并必须在前往[3,3]之前走过[3,2]。
我的问题是,在Bellman-Ford算法中实现它的最佳方法是什么?我知道Dijkstra算法由于负成本而无法使用。
对于每个高度范围内的房间 [0, maxHeight] 是否都进行放松邻居操作,这种方法正确吗?如下所示:
for (int i = height-1; i >= 0; --i) {
for (int j = 0; j < width; ++j) {
int x = i;
int y = j;
if (x > 0) // up
Relax(x, y, x - 1, y);
if (y + 1 < width) // right
Relax(x, y, x, y + 1);
if (y > 0) // left
Relax(x, y, x, y - 1);
if (x + 1 < height) // down
Relax(x, y, x + 1, y);
}
}
那么我该如何查看选定房间的费用以及从房间到出口的路线?