如果你需要问这个问题,那么你可能不熟悉大多数Web应用/服务所做的事情。你可能认为所有软件都是这样做的:
user do an action
│
v
application start processing action
└──> loop ...
└──> busy processing
end loop
└──> send result to user
然而,这并不是 Web 应用程序,或者任何以数据库作为后端的应用程序的工作方式。Web 应用程序会这样做:
user do an action
│
v
application start processing action
└──> make database request
└──> do nothing until request completes
request complete
└──> send result to user
在这种情况下,软件大部分运行时间都在使用0%的CPU时间等待数据库返回。
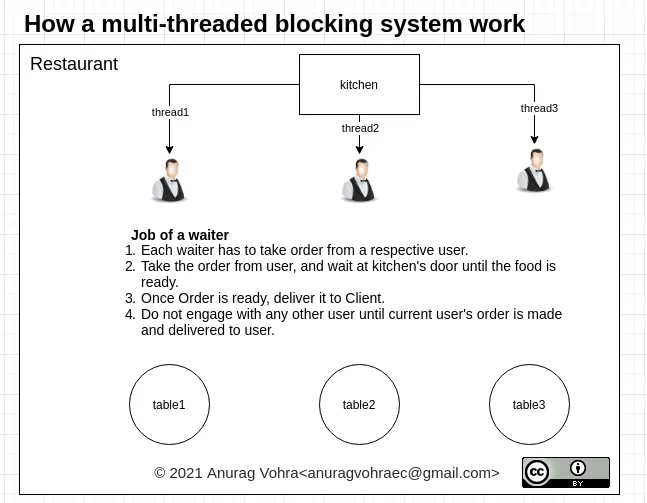
多线程网络应用程序会像这样处理上述工作负载:
request ──> spawn thread
└──> wait for database request
└──> answer request
request ──> spawn thread
└──> wait for database request
└──> answer request
request ──> spawn thread
└──> wait for database request
└──> answer request
因此,线程大部分时间都在使用0%的CPU等待数据库返回数据。在这样做的同时,它们必须为每个线程分配所需的内存,包括每个线程的完全独立的程序堆栈等。此外,他们将不得不启动一个线程,虽然不像启动完整进程那么昂贵,但仍然不是很便宜。
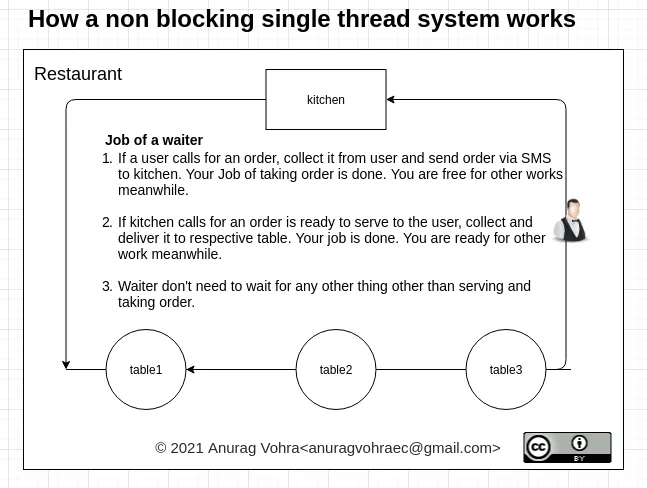
单线程事件循环
既然我们大部分时间都在使用0%的CPU,为什么不在我们不使用CPU时运行一些代码呢?这样,每个请求仍然会获得与多线程应用程序相同数量的CPU时间,但我们不需要启动线程。所以我们这样做:
request ──> make database request
request ──> make database request
request ──> make database request
database request complete ──> send response
database request complete ──> send response
database request complete ──> send response
实际上,这两种方法返回的数据延迟差不多,因为数据库响应时间占主导地位。
这里的主要优点是我们不需要启动一个新线程,因此我们不需要做很多malloc操作,这会减慢速度。
神奇的、看不见的线程
以上两种方法似乎神秘的地方在于如何同时运行工作负载?答案是数据库是多线程的。因此,我们的单线程应用程序实际上利用了另一个进程的多线程行为:数据库。
单线程方法失败的地方
如果需要在返回数据之前进行大量的CPU计算,则单线程应用程序将失败。这里我指的不是处理数据库结果的for循环,那仍然基本上是O(n)。我的意思是像进行傅里叶变换(例如mp3编码)、光线追踪(3D渲染)等操作。
单线程应用程序的另一个缺点是它只能利用单个CPU核心。因此,如果您有一个四核服务器(现在很常见),您没有使用其他3个核心。
多线程方法失败的地方
一个多线程应用如果需要为每个线程分配大量的RAM,那么它很容易失败。首先,内存使用本身意味着您无法处理与单线程应用程序相同数量的请求。更糟糕的是,malloc很慢。分配大量对象(这在现代Web框架中很常见)意味着我们可能最终比单线程应用程序更慢。这就是node.js通常获胜的地方。
其中一种使多线程变得更糟的用例是当您需要在线程中运行另一种脚本语言时。首先,您通常需要为该语言分配整个运行时,然后需要为脚本使用的变量分配内存。
因此,如果您正在使用C、Go或Java编写网络应用程序,则线程的开销通常不会太大。如果您正在编写一个C Web服务器以提供PHP或Ruby,则很容易使用JavaScript、Ruby或Python编写更快的服务器。
混合方法
一些Web服务器使用混合方法。例如,Nginx和Apache2将其网络处理代码实现为事件循环的线程池。每个线程同时运行事件循环,以单线程方式处理请求,但请求在多个线程之间进行负载平衡。
一些单线程架构也采用混合方法。而不是从单个进程启动多个线程,您可以启动多个应用程序 - 例如,在四核机器上启动4个node.js服务器。然后,您可以使用负载均衡器将工作量分配到这些进程中。node.js中的
cluster模块就是这样做的。
实际上,这两种方法在技术上是完全相同的镜像。