我知道这是一个老问题,
但希望这个答案能帮助寻找示例实现的人
自干架以来,所有层都指向
内部而不是
外部。
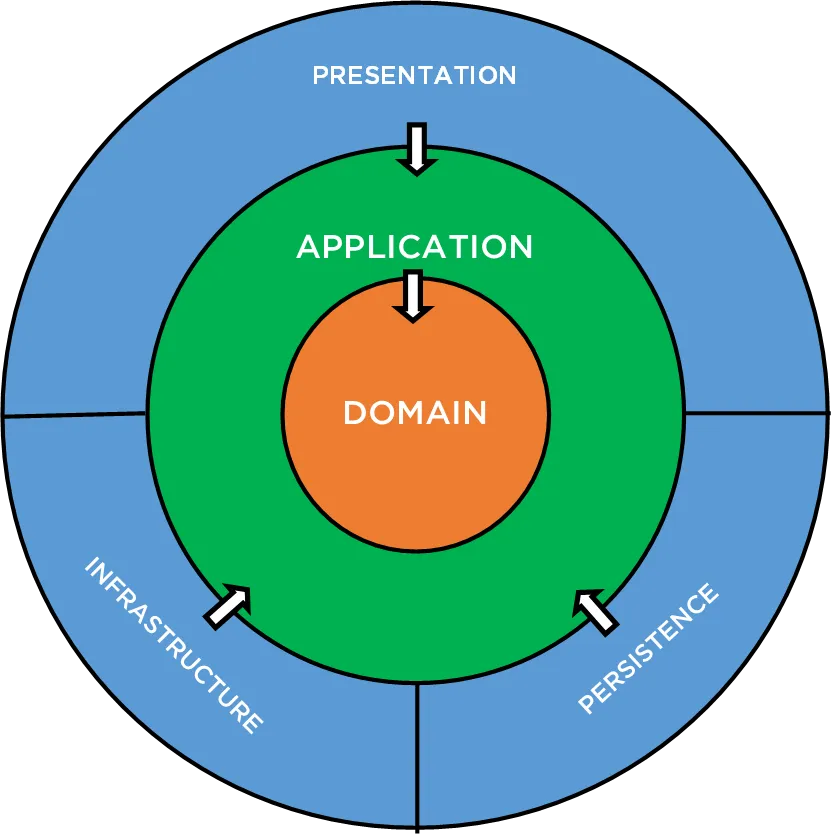
因此,由于事务是应用程序层的问题,我会将其保留在应用程序层中。
在我所做的快速示例中,应用程序层具有接口IDBContext,其中包含我将使用的所有Dbset,如下所示。
public interface IDBContext
{
DbSet<Blog> Blogs { get; set; }
DbSet<Post> Posts{ get; set; }
Task<int> SaveChangesAsync(CancellationToken cancellationToken);
DatabaseFacade datbase { get; }
}
在持久层中,我有该接口的实现
public class ApplicationDbContext : DbContext, IDBContext
{
public ApplicationDbContext(DbContextOptions<ApplicationDbContext> options) :base(options)
{
}
public DbSet<Blog> Blogs { get; set; }
public DbSet<Post> Posts { get; set; }
public DatabaseFacade datbase => Database;
public override async Task<int> SaveChangesAsync(CancellationToken cancellationToken = new CancellationToken())
{
var result = await base.SaveChangesAsync(cancellationToken);
return result;
}
}
回到我通常使用IMediator并遵循CQRM的应用程序层,我制作了这个示例,希望它会有帮助。这是我开始事务的那一行。
await using var transaction = await context.datbase.BeginTransactionAsync();
这是命令处理程序,我在其中使用事务
public async Task<int> Handle(TransactionCommand request, CancellationToken cancellationToken)
{
int updated = 0;
await using var transaction = await context.datbase.BeginTransactionAsync();
try
{
var blog = new Core.Entities.Blog { Url = $"Just test the number sent = {request.number}" };
await context.Blogs.AddAsync(blog);
await context.SaveChangesAsync(cancellationToken);
for (int i = 0; i < 10; i++)
{
var post = new Core.Entities.Post
{
BlogId = blog.BlogId,
Title = $" Title {i} for {blog.Url}"
};
await context.Posts.AddAsync(post);
await context.SaveChangesAsync(cancellationToken);
updated++;
}
var divresult = 5 / request.number;
await transaction.CommitAsync();
}
catch (Exception ex)
{
var msg = ex.Message;
return 0;
}
return updated;
}
这里是我刚刚创建的样例的链接,以便详细解释我的答案。
请记住,我只花了大约15分钟来创建这个示例,仅供参考,如果存在一些不良命名,请谅解 :)
敬礼,