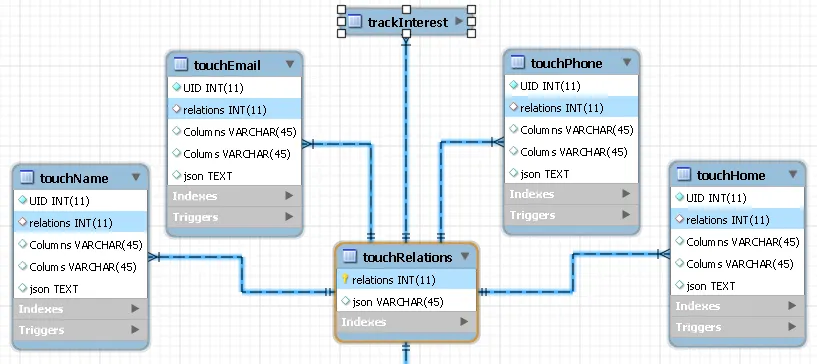
 几个表具有触发器,在更新/插入时生成一个json对象表示行。例如:
几个表具有触发器,在更新/插入时生成一个json对象表示行。例如:{"email": ..., "relations: N" } //<--一个email.json列并将其存储在json列中。
关系只是一个数字连接(如果有对它的专业术语请告诉我),它允许我将多个姓名、电子邮件、电话、住址连接成一个对象 -
例如:the touchRelation.json列
{
"emails": [ {"email": 1@a.com },{"email: 2@a.com"},{"email: N@a.com"}],
"teles" : [ {"tele" : ... },{"tele : ...."},{"tele : ...."}],
"Names" : [ {"Name" : ... },{"Name : ...."},{"Name : ...."}],
"Homes" : [ {"Home" : ... },{"Home : ...."},{"Home : ...."}],
}
我遇到的问题是:1)每次其他表进行数据CRUD操作时更新touchRelations.json将会浪费时间和效率,特别是当多个表同时更新时;2)我可能无法依赖开发人员在每次查询后调用update_Relations_json()函数。有没有一种简单的方法来判断是否已更新了一个或多个表,并且仅在所有表的所有更新完成后重新生成relations.json?
一个可能的解决方案是创建一个“待处理更新”表,将信息存储在队列中,逐个从队列表中插入/更新数据到存储表,然后调用更新函数,但我确信这不是最佳选择。
另一个选择是在数据库中创建一个JSON解析器,读取完整的json关系(来自上面的大型json),更新表,然后构建json对象,但这似乎是对数据库的不良使用。
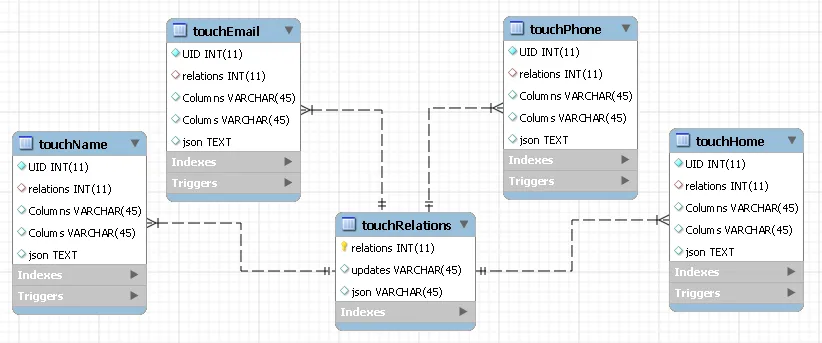 我能想到的最好的方案是创建一个“更新”元数据列,并将默认设置为0。当我们更新电话、电子邮件、姓名或家庭信息时,元数据列会更改为1(表示未提交到关系JSON列的更新)
我能想到的最好的方案是创建一个“更新”元数据列,并将默认设置为0。当我们更新电话、电子邮件、姓名或家庭信息时,元数据列会更改为1(表示未提交到关系JSON列的更新)