我正在使用Ghostscript将源PDF文件转换为PNG图像数组。在将PDF页面转换为PNG图像之前,我需要提取(删除)PDF中的所有文本,以便转换后的页面图像包含除文本以外的所有其他元素。
我是否可以使用Ghostscript来实现这一点,或者我需要寻找不同的工具?
我还对一个能够读取并保存我的源PDF,并删除所有文本的工具感兴趣。
我正在使用Ghostscript将源PDF文件转换为PNG图像数组。在将PDF页面转换为PNG图像之前,我需要提取(删除)PDF中的所有文本,以便转换后的页面图像包含除文本以外的所有其他元素。
我是否可以使用Ghostscript来实现这一点,或者我需要寻找不同的工具?
我还对一个能够读取并保存我的源PDF,并删除所有文本的工具感兴趣。
gs -o no-more-texts.pdf -sDEVICE=pdfwrite -dFILTERTEXT input.pdf
要从输入的PDF中删除所有光栅图像元素,请运行
gs -o no-more-texts.pdf -sDEVICE=pdfwrite -dFILTERIMAGE input.pdf
gs -o no-more-texts.pdf -sDEVICE=pdfwrite -dFILTERVECTOR input.pdf
原始PDF页面截图,包含“图像”、“矢量”和“文本”元素。
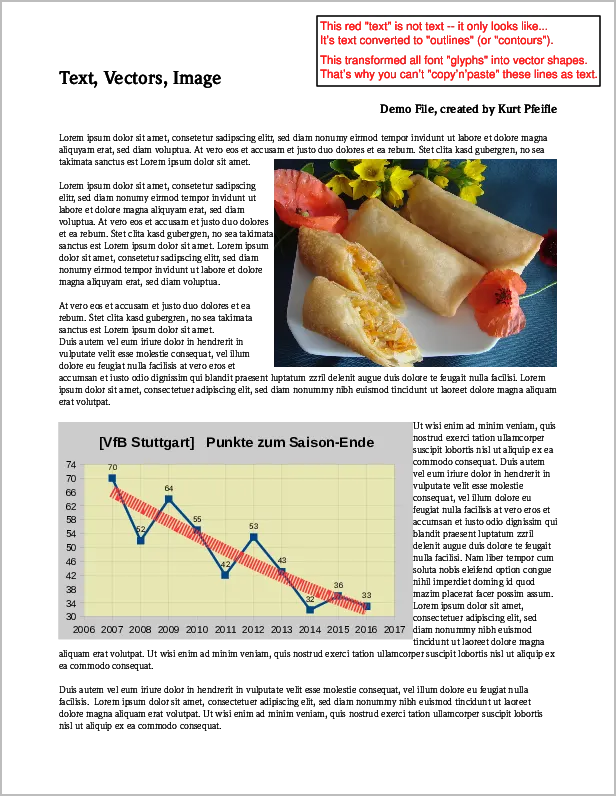
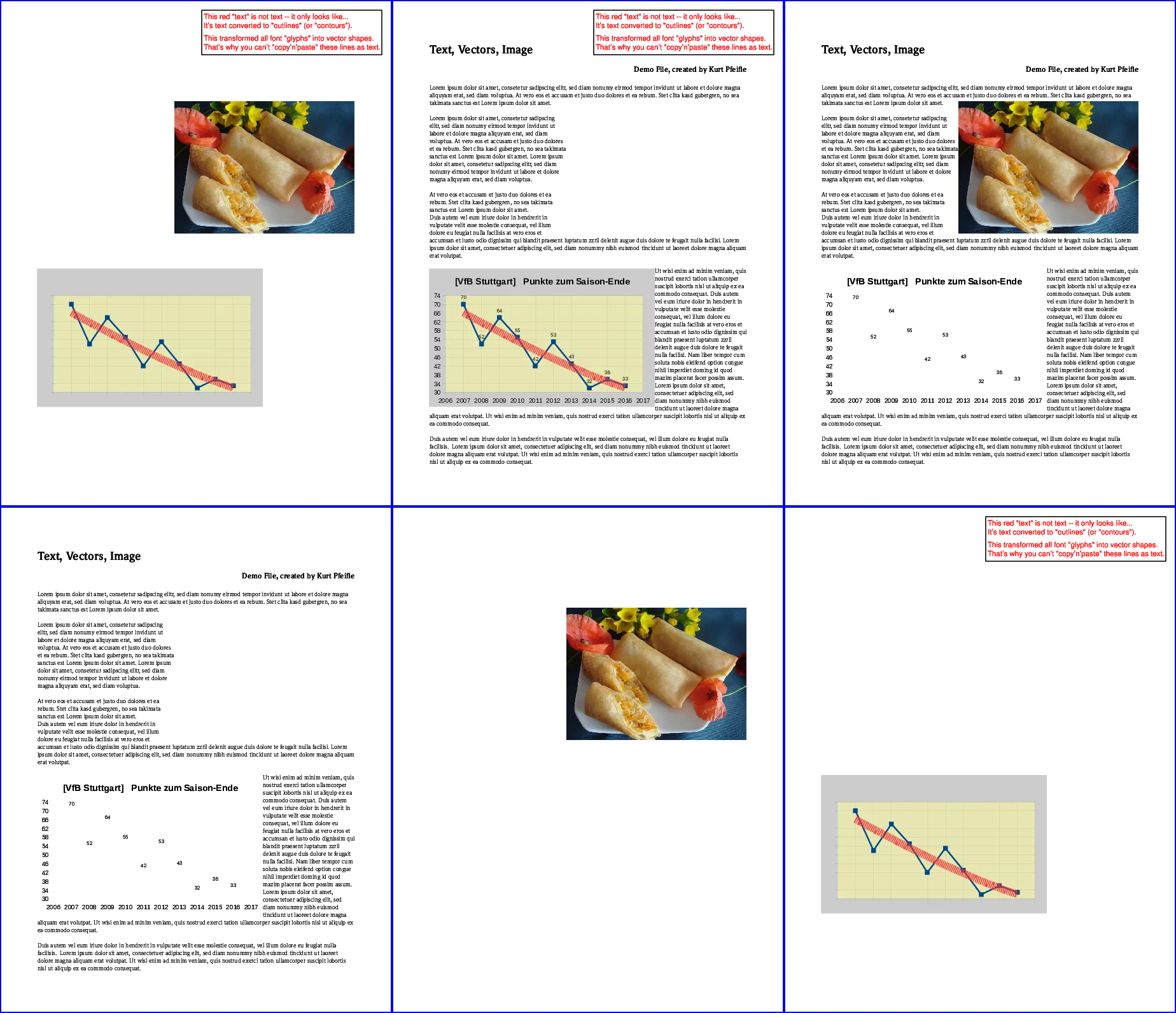
gs -o noIMG.pdf -sDEVICE=pdfwrite -dFILTERIMAGE input.pdf gs -o noTXT.pdf -sDEVICE=pdfwrite -dFILTERTEXT input.pdf gs -o noVCT.pdf -sDEVICE=pdfwrite -dFILTERVECTOR input.pdf下面的图片说明了结果:
gs -o onlyIMG.pdf -sDEVICE=pdfwrite -dFILTERVECTOR -dFILTERTEXT input.pdf gs -o onlyTXT.pdf -sDEVICE=pdfwrite -dFILTERVECTOR -dFILTERIMAGE input.pdf gs -o onlyVCT.pdf -sDEVICE=pdfwrite -dFILTERIMAGE -dFILTERTEXT input.pdf
上排, 从左到右: 所有的“文本”都被删除了; 所有的“图像”都被删除了; 所有的“向量”都被删除了。 下排, 从左到右: 只保留了“文本”; 只保留了“图像”; 只保留了“向量”。
你可以不使用Ghostscript,仅使用文本编辑器就能实现你想要的功能。
使用QPDF将压缩的PDF转换为几乎所有PDF对象内容和流都展开成可读形式的PDF:
qpdf --qdf --object-streams=disable input.pdf editable.pdf
用文本编辑器打开你的新 editable.pdf 文件(它还可以优雅地处理PDF中剩余的二进制数据块,例如字体或ICC资源)。
在PDF对象流内查询所有出现的 TJ 和 Tj 字符串(用于显示文本的PDF操作符),并将其分别替换为JT和jT字符串(未定义的、无意义的PDF操作符)。将文件保存为edited.pdf。
现在按需要将你的 edited.pdf 转换为PNG图像。
edited.pdf 在大多数PDF查看器中仍然会显示,但文本将被省略。不过,通过恢复原始的 TJ/Tj 操作符,就可以轻松地再次恢复文本内容并撤消任何手动修改。
通过上述给定的qpdf命令创建的“规范化”形式中,带有流的对象通常看起来像这样(其中NNN是一个整数):
NNN 0 obj
<<
% Here are the key:value pairs of the object dictionary
/Key1 somevalue1
/Key2 somevalue2
% ... (more key:value pairs)
>>
stream
% Here is the content of the object stream
endstream
endobj
一个"图像流"基本上具有相同的结构。 但是键值对通常包含以下四个条目,以任何顺序(其中NNN和MMM是以像素为单位给出图像的宽度和高度的整数值):
/Type /XObject
/Subtype /Image
/Width NNN
/Height MMM
对不起!我的原始回答中有个重复的拼写错误。我在一些地方使用了 tj,但应该使用 Tj。对于可能造成的任何困惑,我表示歉意。
显然这不是一个标准要求,但最近在#Ghostscript IRC论坛上讨论过。该频道已被记录,您可以在此处找到讨论:
我们最初建议在pdf_ops.ps中将初始文本渲染模式更改为3,但是由于文件使用的是type 3字体,因此对文件没有影响。因此,我们建议在同一文件中修改TJ和Tj的定义。请查看日志中15:37左右的内容。pdf_ops.ps。我现在也下载了GS源代码并找到了这个文件和/TJ、\Tj定义。我猜当我改变这些时需要重新构建它?我需要运行什么命令来删除PDF文件中的文本,之后我进行这些/TJ、/Tj更改? - Primoz Rome
\nBT\n和\nET\n,并删除它们之间的所有内容。 - eithed'和"运算符:它们也用于“显示文本”,类似于Tj和TJ**(但还有一些额外的技巧,比如自动换行或设置单词距离)。 - Kurt Pfeifletj在图像流中实际上是可以遇到的,这就是为什么更改它们会破坏输出PDF的原因吗?正如我所提到的 - 最终我只是删除了BT和ET之间的所有内容,这似乎起了作用。我假设那是包含所有转换的解码文本流 - 因为它也包含了tj- 例如:Td[(C)7(arr)3(ot C)7(ak)8(e......Ł2)]TJ,但这也是:Tm(DRINKS)Tj。 - eithedTJ和Tj字符串:只能在 "PDF对象流" 中(正如我在我的回答中所说),而不是在整个 PDF 文件中 全局 更改(可能会匹配到图像流)... - Kurt Pfeifle