爬虫和网络抓取有区别吗?
如果有区别,那么收集网页数据以供后续在定制搜索引擎中使用的最佳方法是什么?
爬虫和网络抓取有区别吗?
如果有区别,那么收集网页数据以供后续在定制搜索引擎中使用的最佳方法是什么?
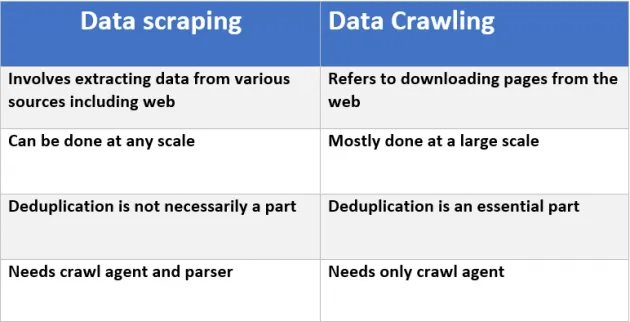
爬取 (Crawling) 通常是指像 Google、Yahoo、MSN 等搜索引擎一样,搜寻任何信息。而抓取 (Scraping) 则专门针对特定网站,获取特定数据,例如价格比较等,因此编码方式也不同。
通常抓取程序将根据其需要抓取的网站进行定制,并且会执行某些良好的爬取程序不会执行的操作,例如:
是的,它们不同。实际上,你可能需要同时使用两者。
(我必须插一句话,因为迄今为止,其他答案没有到达其本质。他们使用例子,但没有清晰地区分。当然,它们来自2010年!)
网页抓取,用最简定义来说,是处理网页文档并从中提取信息的过程。您可以在不进行网页爬行的情况下进行网页抓取。
网页爬行,用最简定义来说,是从一组种子URL开始迭代地查找和获取网页链接的过程。严格来说,要进行网页爬行,您必须进行一定程度的网页抓取(以提取URL。)
澄清其他答案中提到的一些概念:
robots.txt旨在适用于访问网页的任何自动化进程。因此,它适用于爬虫和抓取器。
“正确”的爬虫和抓取器都应准确识别自己。
一些参考资料: