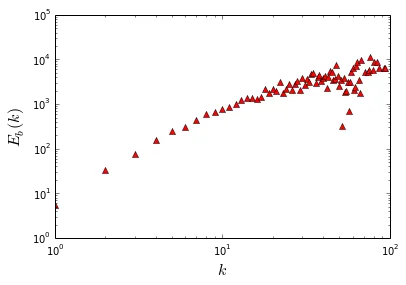
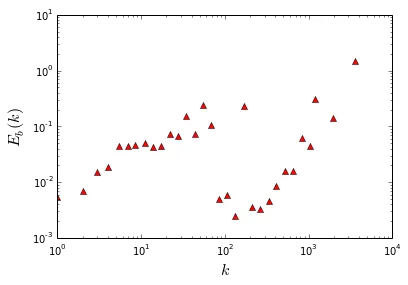
在题为“无标度网络中度相关性的缩放及其对扩散的影响”的论文中,作者定义了量$E_b(k)$来衡量度相关性的程度。
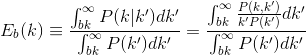
论文
L. K. Gallos, C. Song 和 H. A. Makse,度相关性的缩放及其对无标度网络扩散的影响,Phys. Rev. Lett. 100, 248701 (2008)。
问题
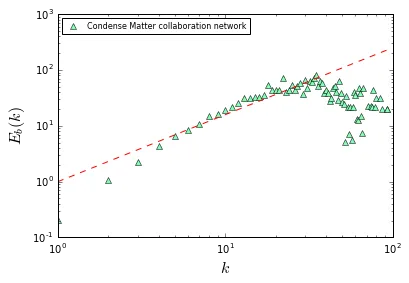
我的问题是如何使用Python计算网络的Eb(k)?我的问题是我无法复现作者的结果。我使用Condense Matter数据进行测试,Eb(k)的结果显示在上面的图中。 您可以看到我的图中一个问题是Eb(k)远大于1!!!我还尝试了互联网(As level数据)和WWW数据,但问题仍然存在。毫无疑问,我的算法或代码出了严重的问题。您可以复现我的结果,并与作者进行比较。非常感谢您提供的解决方案或建议。我将在下面介绍我的算法和Python脚本。
我按照以下步骤进行:
- 对于每条边,找到k=k的边以及k' > 3k的边。这些边的概率表示为P(k, k')
- 对于节点,获取度数大于b*k的节点比例,表示为p(k'),因此我们也可以得到k'*p(k')
- 获取分子P1:p1 = \sum P(k, k')/k'*P(k')
- 获取分母P2:P2 = \sum P(k')
- Eb(k) = p1/p2
Python脚本
以下是Python脚本:
%matplotlib inline
import networkx as nx
import matplotlib.cm as cm
import matplotlib.pyplot as plt
from collections import defaultdict
def ebks(g, b):
edge_dict = defaultdict(lambda: defaultdict(int))
degree_dict = defaultdict(int)
edge_degree = [sorted(g.degree(e).values()) for e in g.edges()]
for e in edge_degree:
edge_dict[e[0]][e[-1]] +=1
for i in g.degree().values():
degree_dict[i] +=1
edge_number = g.number_of_edges()
node_number = g.number_of_nodes()
ebks, ks = [], []
for k1 in edge_dict:
p1, p2 = 0, 0
for k2 in edge_dict[k1]:
if k2 >= b*k1:
pkk = float(edge_dict[k1][k2])/edge_number
pk2 = float(degree_dict[k2])/node_number
k2pk2 = k2*pk2
p1 += pkk/k2pk2
for k in degree_dict:
if k>=b*k1:
pk = float(degree_dict[k])/node_number
p2 += pk
if p2 > 0:
ebks.append(p1/p2)
ks.append(k1)
return ebks, ks
我使用ca-CondMat数据进行测试,您可以从此网址下载:http://snap.stanford.edu/data/ca-CondMat.html
# Load the data
# Remember to change the file path to your own
ca = nx.Graph()
with open ('/path-of-your-file/ca-CondMat.txt') as f:
for line in f:
if line[0] != '#':
x, y = line.strip().split('\t')
ca.add_edge(x,y)
nx.info(ca)
#calculate ebk
ebk, k = ebks(ca, b=3)
plt.plot(k,ebk,'r^')
plt.xlabel(r'$k$', fontsize = 16)
plt.ylabel(r'$E_b(k)$', fontsize = 16)
plt.xscale('log')
plt.yscale('log')
plt.show()
更新:问题尚未解决。
def ebkss(g, b, x):
edge_dict = defaultdict(lambda: defaultdict(int))
degree_dict = defaultdict(int)
edge_degree = [sorted(g.degree(e).values()) for e in g.edges()]
for e in edge_degree:
edge_dict[e[0]][e[-1]] +=1
for i in g.degree().values():
degree_dict[i] +=1
edge_number = g.number_of_edges()
node_number = g.number_of_nodes()
ebks, ks = [], []
for k1 in edge_dict:
p1, p2 = 0, 0
nk2k = np.sum(edge_dict[k1].values())
pk1 = float(degree_dict[k1])/node_number
k1pk1 = k1*pk1
for k2 in edge_dict[k1]:
if k2 >= b*k1:
pk2k = float(edge_dict[k1][k2])/nk2k
pk2 = float(degree_dict[k2])/node_number
k2pk2 = k2*pk2
p1 += (pk2k*k1pk1)/k2pk2
for k in degree_dict:
if k>=b*k1:
pk = float(degree_dict[k])/node_number
p2 += pk
if p2 > 0:
ebks.append(p1/p2**x)
ks.append(k1)
return ebks, ks