我对Java字符串常量池有以下理解(如果我错了,请纠正):
当源代码被编译时,编译器会查找程序中所有的字符串字面量(放在双引号中的字符串),并在堆区域创建不同的对象(无重复项),并在特殊的内存区域中维护它们的引用,称为字符串常量池(方法区内的一个区域)。任何其他字符串对象都是在运行时创建的。
假设我们的代码有以下语句:
String a = "abc"; //Line 1
String b = "xyz"; //Line 2
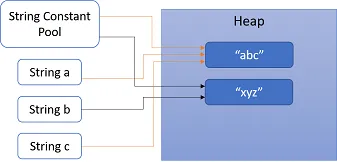
String c = "abc"; //Line 3
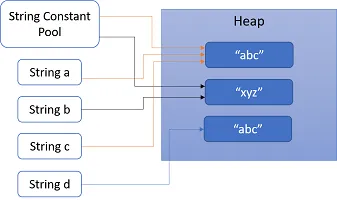
String d = new String("abc"): //Line 4
当上述代码被编译时,
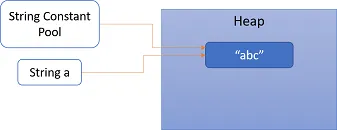
第1行:在堆中创建了一个字符串对象 "abc",并且该对象被变量 a 和字符串常量池所引用。
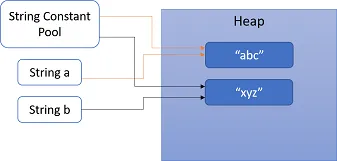
第二行:编译器在字符串常量池中搜索是否存在指向对象“xyz”的引用。但没有找到。因此,它创建了对象“xyz”并将其引用放入字符串常量池。
第四行:第四行中的文字已经存在于字符串常量池中,因此不会再次添加到池中。然而,在运行时,另一个字符串对象被创建并存储在变量d中。
现在我有以下问题/疑问:
- 上述描述的是否完全准确?
- 编译器如何创建对象?据我所知,对象是在运行时创建的,堆是一个运行时内存区域。那么,在编译时如何以及在哪里创建字符串对象!
- 源代码可以在一台机器上编译并在另一台机器上运行。或者,即使在同一台机器上编译和运行,它们也可以在不同的时间编译和运行。那么,如何恢复这些(在编译时创建的)对象?
- 当我们对一个字符串进行国际化处理时会发生什么。