根据确保数据在磁盘上的信息(http://winntfs.com/2012/11/29/windows-write-caching-part-2-an-overview-for-application-developers/),即使发生例如停电等情况,似乎在Windows平台上需要依赖其“fsync”版本FlushFileBuffers来获得最佳保证,即缓存实际上从磁盘设备缓存中刷新到存储介质本身。如果这些信息是正确的,则FILE_FLAG_NO_BUFFERING与FILE_FLAG_WRITE_THROUGH的组合不能确保刷新设备缓存,而只对文件系统缓存产生影响。
// Code updated to reflect new results as discussed in answer below.
// 26/Aug/2013: Code updated again to reflect results as discussed in follow up question.
// 28/Aug/2012: Increased file stream buffer to ensure 8 page flushes.
class Program
{
static void Main(string[] args)
{
BenchSequentialWrites(reuseExistingFile:false);
}
public static void BenchSequentialWrites(bool reuseExistingFile = false)
{
Tuple<string, bool, bool, bool, bool>[] scenarios = new Tuple<string, bool, bool, bool, bool>[]
{ // output csv, fsync?, fill end?, write through?, mem map?
Tuple.Create("timing FS-E-B-F.csv", true, false, false, false),
Tuple.Create("timing NS-E-B-F.csv", false, false, false, false),
Tuple.Create("timing FS-LB-B-F.csv", true, true, false, false),
Tuple.Create("timing NS-LB-B-F.csv", false, true, false, false),
Tuple.Create("timing FS-E-WT-F.csv", true, false, true, false),
Tuple.Create("timing NS-E-WT-F.csv", false, false, true, false),
Tuple.Create("timing FS-LB-WT-F.csv", true, true, true, false),
Tuple.Create("timing NS-LB-WT-F.csv", false, true, true, false),
Tuple.Create("timing FS-E-B-MM.csv", true, false, false, true),
Tuple.Create("timing NS-E-B-MM.csv", false, false, false, true),
Tuple.Create("timing FS-LB-B-MM.csv", true, true, false, true),
Tuple.Create("timing NS-LB-B-MM.csv", false, true, false, true),
Tuple.Create("timing FS-E-WT-MM.csv", true, false, true, true),
Tuple.Create("timing NS-E-WT-MM.csv", false, false, true, true),
Tuple.Create("timing FS-LB-WT-MM.csv", true, true, true, true),
Tuple.Create("timing NS-LB-WT-MM.csv", false, true, true, true),
};
foreach (var scenario in scenarios)
{
Console.WriteLine("{0,-12} {1,-16} {2,-16} {3,-16} {4:F2}", "Total pages", "Interval pages", "Total time", "Interval time", "MB/s");
CollectGarbage();
var timingResults = SequentialWriteTest("test.data", !reuseExistingFile, fillEnd: scenario.Item3, nPages: 200 * 1000, fSync: scenario.Item2, writeThrough: scenario.Item4, writeToMemMap: scenario.Item5);
using (var report = File.CreateText(scenario.Item1))
{
report.WriteLine("Total pages,Interval pages,Total bytes,Interval bytes,Total time,Interval time,MB/s");
foreach (var entry in timingResults)
{
Console.WriteLine("{0,-12} {1,-16} {2,-16} {3,-16} {4:F2}", entry.Item1, entry.Item2, entry.Item5, entry.Item6, entry.Item7);
report.WriteLine("{0},{1},{2},{3},{4},{5},{6}", entry.Item1, entry.Item2, entry.Item3, entry.Item4, entry.Item5.TotalSeconds, entry.Item6.TotalSeconds, entry.Item7);
}
}
}
}
public unsafe static IEnumerable<Tuple<long, long, long, long, TimeSpan, TimeSpan, double>> SequentialWriteTest(
string fileName,
bool createNewFile,
bool fillEnd,
long nPages,
bool fSync = true,
bool writeThrough = false,
bool writeToMemMap = false,
long pageSize = 4096)
{
// create or open file and if requested fill in its last byte.
var fileMode = createNewFile ? FileMode.Create : FileMode.OpenOrCreate;
using (var tmpFile = new FileStream(fileName, fileMode, FileAccess.ReadWrite, FileShare.ReadWrite, (int)pageSize))
{
Console.WriteLine("Opening temp file with mode {0}{1}", fileMode, fillEnd ? " and writing last byte." : ".");
tmpFile.SetLength(nPages * pageSize);
if (fillEnd)
{
tmpFile.Position = tmpFile.Length - 1;
tmpFile.WriteByte(1);
tmpFile.Position = 0;
tmpFile.Flush(true);
}
}
// Make sure any flushing / activity has completed
System.Threading.Thread.Sleep(TimeSpan.FromMinutes(1));
System.Threading.Thread.SpinWait(50); // warm up.
var buf = new byte[pageSize];
new Random().NextBytes(buf);
var ms = new System.IO.MemoryStream(buf);
var stopwatch = new System.Diagnostics.Stopwatch();
var timings = new List<Tuple<long, long, long, long, TimeSpan, TimeSpan, double>>();
var pageTimingInterval = 8 * 2000;
var prevPages = 0L;
var prevElapsed = TimeSpan.FromMilliseconds(0);
// Open file
const FileOptions NoBuffering = ((FileOptions)0x20000000);
var options = writeThrough ? (FileOptions.WriteThrough | NoBuffering) : FileOptions.None;
using (var file = new FileStream(fileName, FileMode.Open, FileAccess.ReadWrite, FileShare.ReadWrite, (int)(16 *pageSize), options))
{
stopwatch.Start();
if (writeToMemMap)
{
// write pages through memory map.
using (var mmf = MemoryMappedFile.CreateFromFile(file, Guid.NewGuid().ToString(), file.Length, MemoryMappedFileAccess.ReadWrite, null, HandleInheritability.None, true))
using (var accessor = mmf.CreateViewAccessor(0, file.Length, MemoryMappedFileAccess.ReadWrite))
{
byte* base_ptr = null;
accessor.SafeMemoryMappedViewHandle.AcquirePointer(ref base_ptr);
var offset = 0L;
for (long i = 0; i < nPages / 8; i++)
{
using (var memStream = new UnmanagedMemoryStream(base_ptr + offset, 8 * pageSize, 8 * pageSize, FileAccess.ReadWrite))
{
for (int j = 0; j < 8; j++)
{
ms.CopyTo(memStream);
ms.Position = 0;
}
}
FlushViewOfFile((IntPtr)(base_ptr + offset), (int)(8 * pageSize));
offset += 8 * pageSize;
if (fSync)
FlushFileBuffers(file.SafeFileHandle);
if (((i + 1) * 8) % pageTimingInterval == 0)
timings.Add(Report(stopwatch.Elapsed, ref prevElapsed, (i + 1) * 8, ref prevPages, pageSize));
}
accessor.SafeMemoryMappedViewHandle.ReleasePointer();
}
}
else
{
for (long i = 0; i < nPages / 8; i++)
{
for (int j = 0; j < 8; j++)
{
ms.CopyTo(file);
ms.Position = 0;
}
file.Flush(fSync);
if (((i + 1) * 8) % pageTimingInterval == 0)
timings.Add(Report(stopwatch.Elapsed, ref prevElapsed, (i + 1) * 8, ref prevPages, pageSize));
}
}
}
timings.Add(Report(stopwatch.Elapsed, ref prevElapsed, nPages, ref prevPages, pageSize));
return timings;
}
private static Tuple<long, long, long, long, TimeSpan, TimeSpan, double> Report(TimeSpan elapsed, ref TimeSpan prevElapsed, long curPages, ref long prevPages, long pageSize)
{
var intervalPages = curPages - prevPages;
var intervalElapsed = elapsed - prevElapsed;
var intervalPageSize = intervalPages * pageSize;
var mbps = (intervalPageSize / (1024.0 * 1024.0)) / intervalElapsed.TotalSeconds;
prevElapsed = elapsed;
prevPages = curPages;
return Tuple.Create(curPages, intervalPages, curPages * pageSize, intervalPageSize, elapsed, intervalElapsed, mbps);
}
private static void CollectGarbage()
{
GC.Collect();
GC.WaitForPendingFinalizers();
System.Threading.Thread.Sleep(200);
GC.Collect();
GC.WaitForPendingFinalizers();
System.Threading.Thread.SpinWait(10);
}
[DllImport("kernel32.dll", SetLastError = true)]
static extern bool FlushViewOfFile(
IntPtr lpBaseAddress, int dwNumBytesToFlush);
[DllImport("kernel32.dll", SetLastError = true, CharSet = CharSet.Auto)]
static extern bool FlushFileBuffers(SafeFileHandle hFile);
}
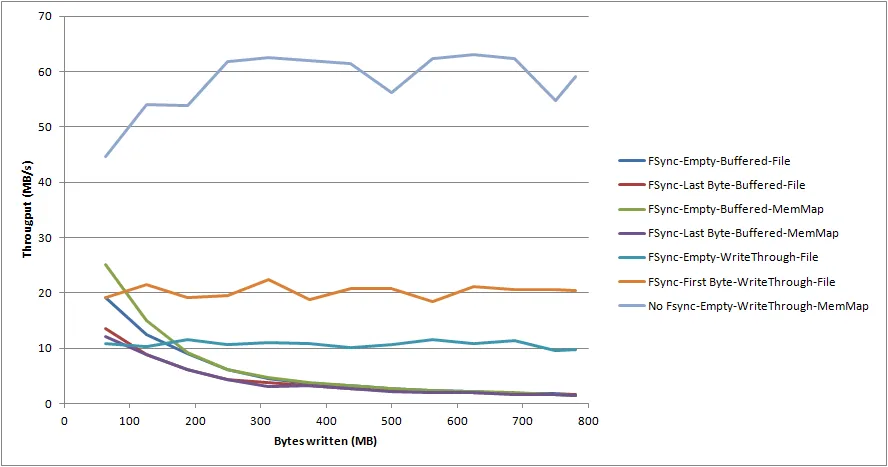
我所获得的性能结果(64位Win 7,慢速磁盘)并不令人鼓舞。看起来,“fsync”性能非常依赖于要刷新的文件大小,以至于它占据了时间的主导地位,而不是要刷新的“脏”数据量。下面的图表显示了小型基准应用程序的4个不同设置选项的结果。
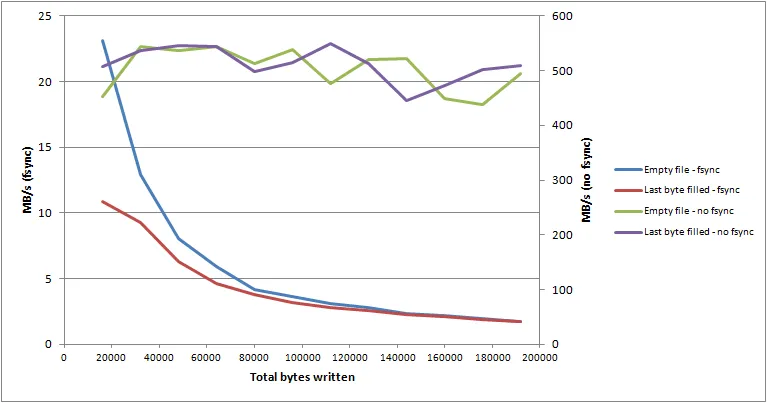
如您所见,“fsync”的性能随文件大小指数级下降(直到几个GB时真的会停滞不前)。此外,磁盘本身似乎并没有做很多事情(即资源监视器显示其活动时间只有几个百分点左右,而其磁盘队列在大部分时间内都是空闲的)。
我显然预计“fsync”性能要比执行正常的缓冲刷新差得多,但我预计它会更或多或少保持稳定,并且与文件大小无关。如此一来,它似乎表明它不能与单个大型文件组合使用。
是否有人能够提供解释、不同的经验或不同的解决方案,以确保数据在磁盘上,并具有较为恒定、可预测的性能呢?
更新 请参见下面答案中的新信息。