ConcurrentHashMap相比于HashMap在性能上如何表现,特别是.get()操作(我对只有少量项目的情况特别感兴趣,例如0-5000的范围内)?
是否有任何理由不使用ConcurrentHashMap而使用HashMap?
(我知道不允许使用null值)
更新
仅仅为了澄清,显然,在实际并发访问的情况下性能会受到影响,但在没有并发访问的情况下性能如何比较?
ConcurrentHashMap相比于HashMap在性能上如何表现,特别是.get()操作(我对只有少量项目的情况特别感兴趣,例如0-5000的范围内)?
是否有任何理由不使用ConcurrentHashMap而使用HashMap?
(我知道不允许使用null值)
更新
仅仅为了澄清,显然,在实际并发访问的情况下性能会受到影响,但在没有并发访问的情况下性能如何比较?
ScalaMeter,我创建了HashMap和ConcurrentHashMap的add、get和remove测试,分别在以下两种情况下进行:
HashMap不是线程安全的,所以我为每个线程创建了一个单独的HashMap,但使用了一个共享的ConcurrentHashMap。代码可以在我的repo上找到。
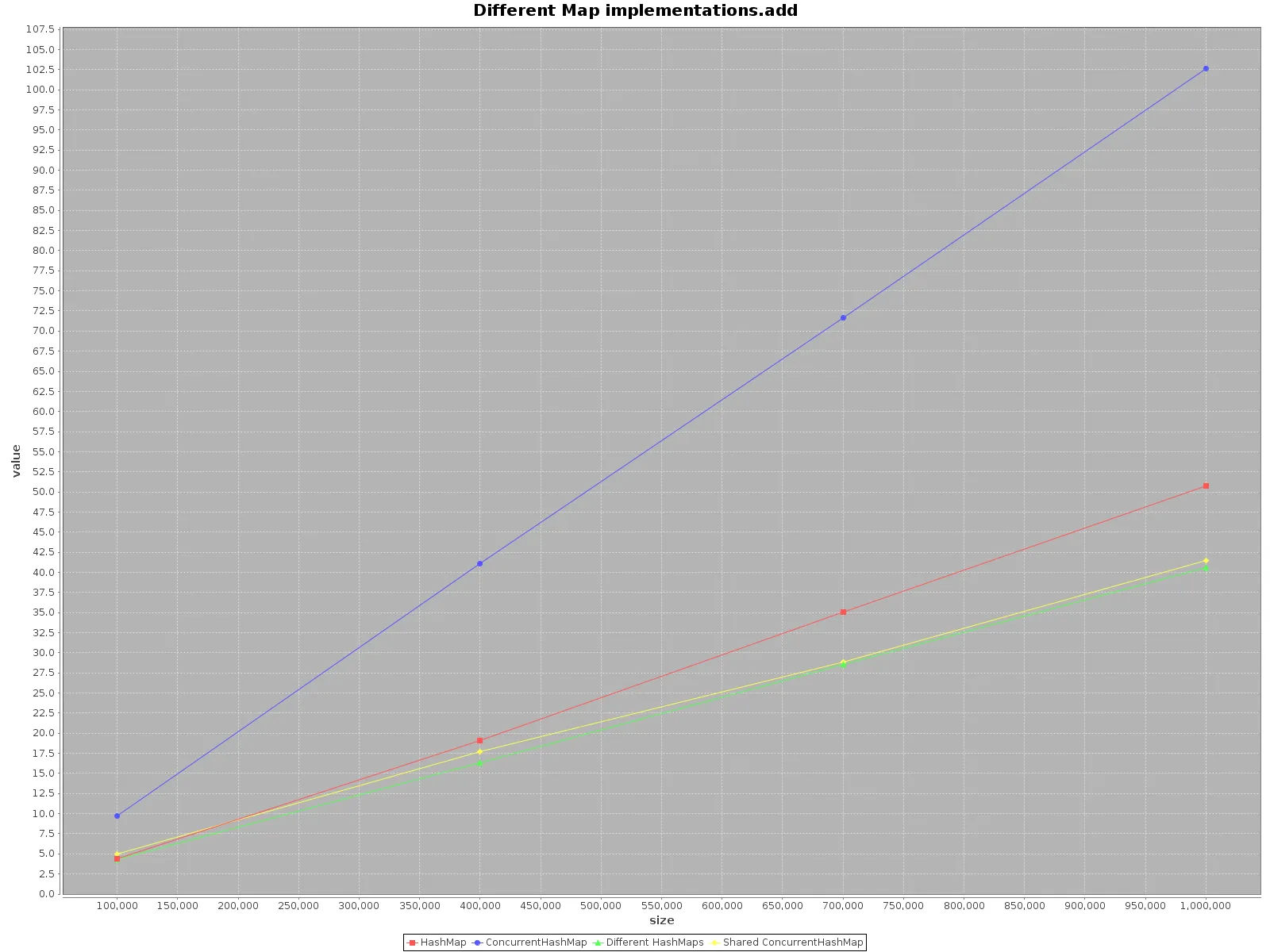
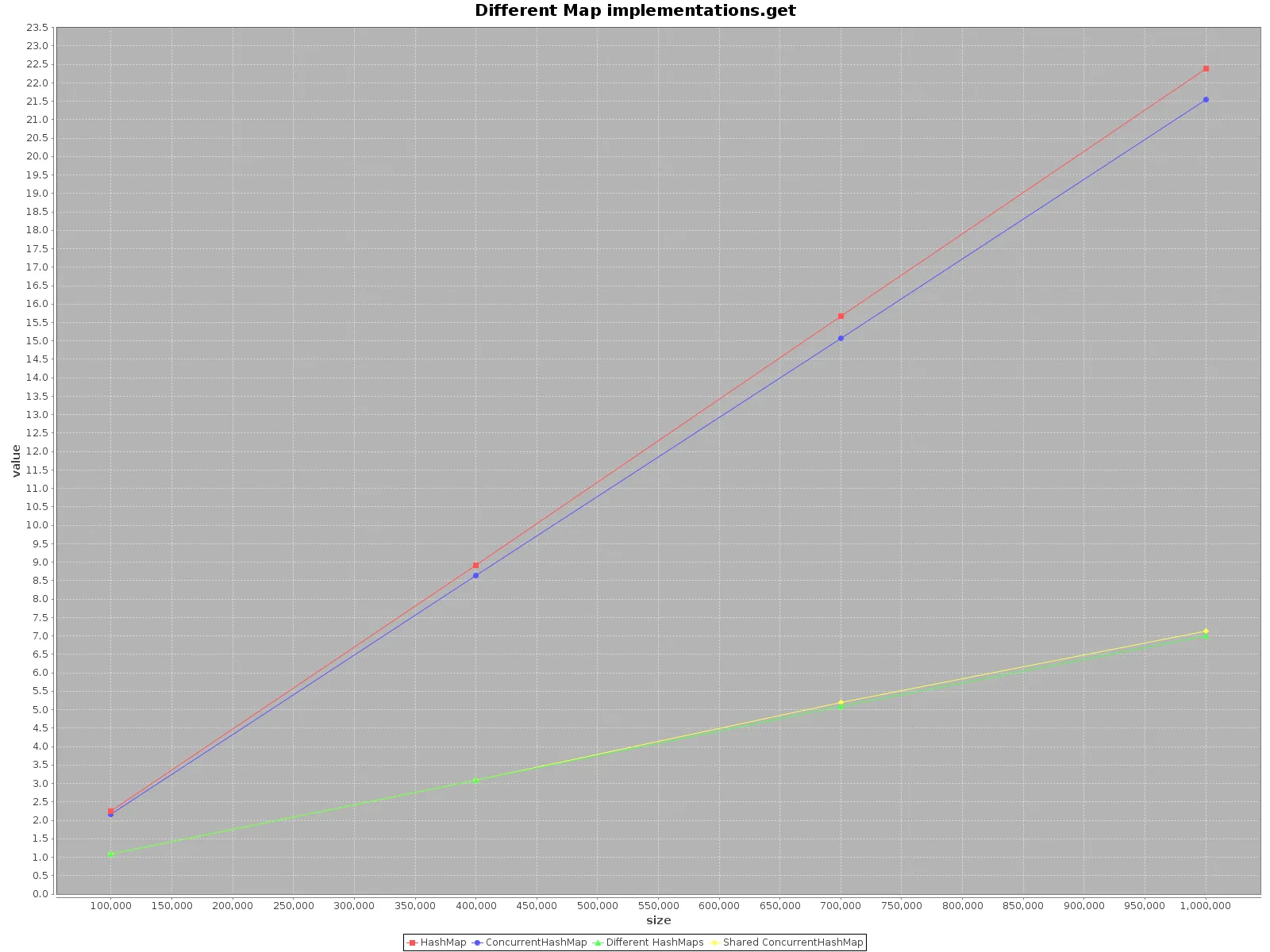
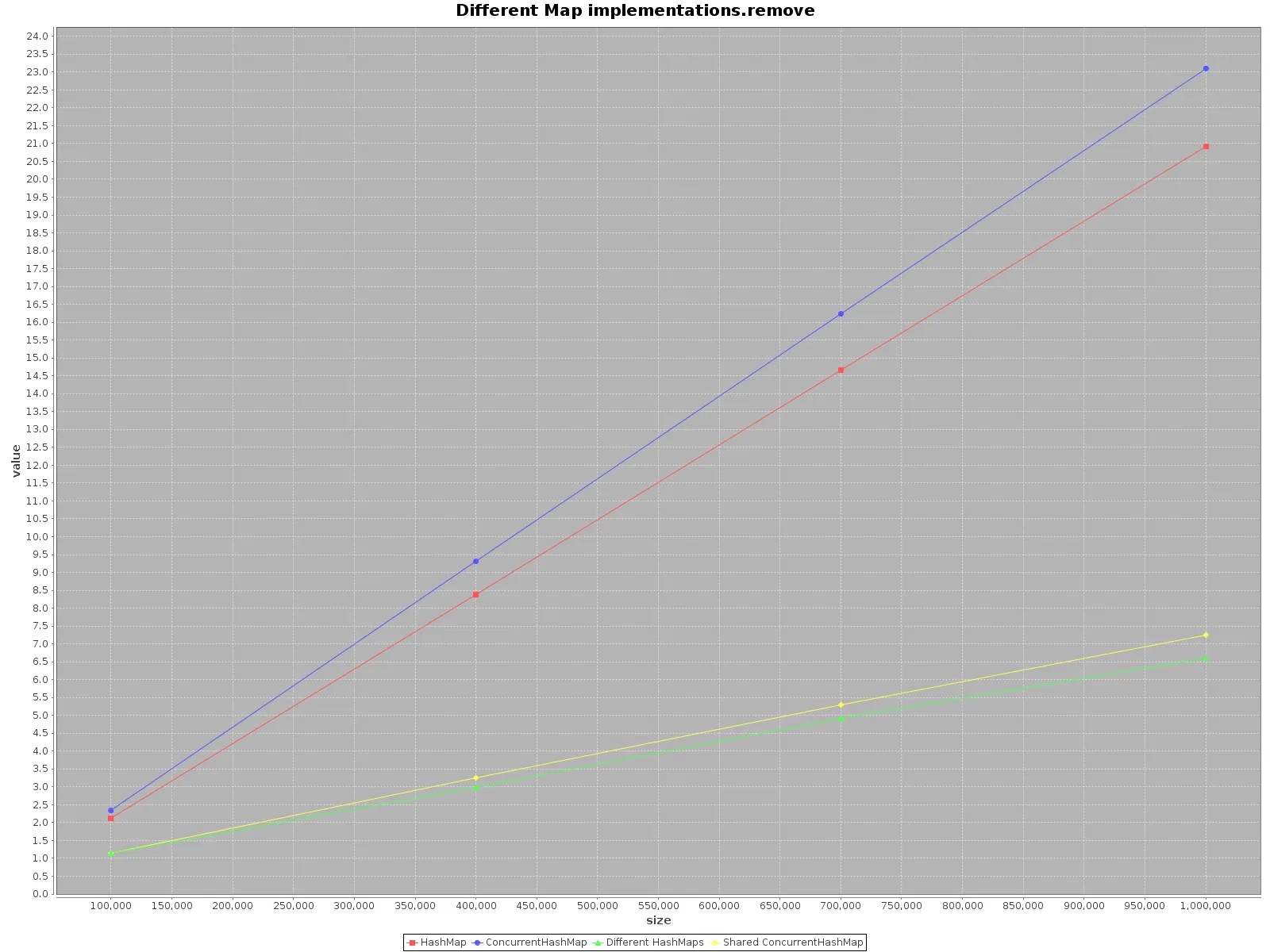
如果您想尽可能快地操作数据,请使用所有可用的线程。这似乎很明显,每个线程有1/n的完整工作要做。
如果选择单个线程访问,请使用HashMap,它更快。对于add方法,效率甚至高达3倍。只有get在ConcurrentHashMap上更快,但并不多。
在使用多个线程操作ConcurrentHashMap时,与为每个线程操作单独的HashMaps相比,效果类似。因此,无需将数据分区到不同的结构中。
总之,当您使用单个线程时,ConcurrentHashMap的性能较差,但添加更多线程来完成工作肯定会加速进程。
测试平台
AMD FX6100,16GB Ram
Xubuntu 16.04,Oracle JDK 8更新91,Scala 2.11.8
线程安全是一个复杂的问题。如果你想使一个对象线程安全,请有意识地这样做,并记录这个选择。如果你的类是线程安全的,当它简化了用户的使用时,使用你的类的人会感谢你,但如果曾经是线程安全的对象在未来版本中变得不再安全,他们会咒骂你。线程安全虽然非常好,但并不仅限于圣诞节!
现在回到你的问题:
ConcurrentHashMap(至少在Sun当前的实现中)通过将底层映射分成若干个单独的桶来工作。获取元素本身不需要任何锁定,但它确实使用原子/易失性操作,这意味着一个内存屏障(潜在的非常昂贵,并且干扰其他可能的优化)。
即使在单线程情况下JIT编译器可以消除所有原子操作的开销,还是需要决定查找哪个桶——尽管这是一个相对较快的计算,但仍然不可能消除。
至于选择使用哪种实现,选择可能很简单。
如果这是一个静态字段,则几乎肯定要使用ConcurrentHashMap,除非测试表明这会严重影响性能。你的类与该类的实例具有不同的线程安全期望。
如果这是一个局部变量,那么HashMap可能就足够了——除非你知道对象的引用可能泄漏到另一个线程中。通过编写Map接口,可以在以后轻松地更改它,如果发现问题。
如果这是一个实例字段,并且该类未设计为线程安全,请将其标记为不安全,并使用HashMap。ConcurrentHashMap 的实现在几乎所有情况下都比 HashMap 更快。没有提供支持此说法的数据,但我很想看到这个结果得到验证... - Dylan Watson我建议你进行测量,因为(其中一个原因是)可能会与你存储的特定对象的哈希分布有关。
标准哈希表没有并发保护,而并发哈希表有。在并发哈希表出现之前,您可以将哈希表包装起来以获得线程安全的访问,但这是粗略的粒度锁定,意味着所有并发访问都会串行化,这可能会影响性能。
并发哈希表使用锁分离,仅锁定受特定锁定影响的项。如果您正在运行像HotSpot这样的现代VM,则VM将尝试使用锁定偏好、锁合并和消除(lock biasing, coarsaning and ellision)等优化技术,因此您只在需要时才付出锁定的代价。
总之,如果您的哈希表将被并发线程访问,并且您需要保证其状态的一致性视图,请使用并发哈希表。
不清楚你的意思。如果你需要线程安全,几乎没有选择 - 只有ConcurrentHashMap。但是在get()调用中,它肯定会有性能/内存惩罚 - 访问易失性变量并锁定(如果你运气不好)。