在Aho Ullman和Sethi的《编译器构造》中,它指出源程序的输入字符字符串被划分为具有逻辑含义的字符序列,称为标记(tokens),而词素(lexemes)是组成标记的序列,那么它们之间的基本区别是什么?
令牌和词素有什么区别?
112
- user1707873
4
1编译器构造,作者Aho、Ullman和Sethi——这是龙书吗?我找不到这本书? - Drazisil
“龙书”是由Alfred V. Aho、Monica S. Lam、Ravi Sethi和Jeffrey D. Ullman合著的《编译器原理、技术与工具》。 - Peter Mortensen
这可能是对“龙书”的粗略引用(例如,在第一个修订版中,作者的名字没有大写)。它也省略了重要的标点符号。 - Peter Mortensen
这可能是对《龙书》的马虎引用(例如,在第一个修订版中,作者的名字没有大写)。它还遗漏了关键的标点符号。 - undefined
14个回答
147
使用编译原理,技术和工具,第二版 (WorldCat) 一书,作者为Aho、Lam、Sethi和Ullman,又称为紫龙书,
词素 pg. 111
词素是源程序中与令牌模式匹配并被词法分析器识别为该令牌实例的字符序列。
令牌 pg. 111
令牌是由令牌名称和可选属性值组成的一对。令牌名称是表示词法单元种类的抽象符号,例如特定关键字或表示标识符的输入字符序列。令牌名称是解析器处理的输入符号。
模式 pg. 111
一个模式是对令牌的词素可能采用的形式的描述。对于作为标记的关键字,模式只是形成关键字的字符序列。对于标识符和一些其他标记,模式是更复杂的结构,可以匹配许多字符串。图3.2:令牌示例,第112页。
[Token] [Informal Description] [Sample Lexemes]
if characters i, f if
else characters e, l, s, e else
comparison < or > or <= or >= or == or != <=, !=
id letter followed by letters and digits pi, score, D2
number any numeric constant 3.14159, 0, 6.02e23
literal anything but ", surrounded by "'s "core dumped"
为了更好地理解与词法分析器和语法分析器的关系,我们将从语法分析器开始,逐步向输入方向推进。
为了更容易设计语法分析器,语法分析器不直接使用输入,而是通过词法分析器生成的令牌列表进行处理。在图3.2的令牌列中,我们看到令牌如
if、else、comparison、id、number和literal等名称。通常,在词法分析器/语法分析器中,一个令牌是一个结构体,它不仅包含令牌的名称,还包括组成令牌的字符/符号以及组成令牌的字符字符串的起始和结束位置,其中起始和结束位置用于错误报告、高亮显示等。现在词法分析器接收字符/符号的输入,并使用词法分析器的规则将输入字符/符号转换为记号。现在,与词法分析器/解析器一起工作的人有自己经常使用的术语。当您认为由字符/符号组成的记号序列时,这些人称之为词素。因此,当您看到词素时,只需想象表示记号的一系列字符/符号即可。在比较示例中,字符/符号的序列可以是不同的模式,例如
<或>或else或3.14等。另一种思考两者之间关系的方法是,记号是解析器使用的编程结构,具有名为词素的属性,该属性包含来自输入的字符/符号。现在,如果您查看代码中大多数标记的定义,可能不会看到词素作为标记的属性之一。这是因为标记更可能保留表示记号的字符/符号的开始和结束位置以及词素,字符/符号序列可以按需从开始和结束位置派生,因为输入是静态的。
- Guy Coder
6
14在口语的编译器使用中,人们倾向于将这两个术语互换使用。当你需要时,精确的区分是很好的。 - Ira Baxter
1虽然这不是一个纯粹的计算机科学定义,但以下是自然语言处理中与此相关的一个定义,来自于《词汇语义学导论》(http://www3.cs.stonybrook.edu/~ychoi/cse507/slides/03-lexsem.pdf):“词典中的一个单独条目”。 - Guy Coder
1绝对清晰的解释。这就是应该在天堂里解释事情的方式。 - Timur Fayzrakhmanov
很好的解释。我还有一个疑问,我也读到了解析阶段,解析器从词法分析器那里请求令牌,因为解析器无法验证令牌。您能否请以解析器阶段的简单输入为例解释何时解析器会向词法分析器请求令牌? - Prasanna
@PrasannaSasne
你能否请以解析器阶段的简单输入为例来解释,解析器何时向词法分析器请求令牌。 SO不是讨论网站。这是一个新问题,需要作为一个新问题提出。 - Guy Coder@GuyCoder,我已经发布了我的问题,想要一些关于符号表的信息。你能否帮忙看一下?
https://stackoverflow.com/questions/63820620/what-values-are-stored-into-symbol-table-in-compiler-construction。我也会在另一个线程中发布上述问题。谢谢。 - Prasanna44
当源程序输入到词法分析器中时,它会首先将字符分解为词素序列。然后使用这些词素构建出标记,其中词素被映射到标记中。例如,变量名为myVar的变量将被映射到一个标记,其内容为<id, "num">,其中"num"应该指向符号表中该变量的位置。
简而言之:
- 词素是从字符输入流中获取的单词。
- 标记是词素映射成标记名称和属性值。
例如:
x = a + b * 2
将产生以下词素:{x, =, a, +, b, *, 2}
对应的标记为:{<id, 0>, <=>, <id, 1>, <+>, <id, 2>, <*>, <id, 3>}
- William
2
3应该是<id, 3>吗?因为2不是标识符。 - Aditya
但是在哪里说x是标识符?这是否意味着符号表是一个三列表,具有“名称”=x,“类型”=“标识符(id)”,指针=“0”作为特定条目?那么它必须还有其他条目,如“名称”=while,“类型”=“关键字”,指针=“21”吗? - user4831795
10
词元 - 词元是编程语言中最低级别的语法单元,由一串字符组成。
记号 - 记号是一个语法类别,形成了一类词元,表示词元属于哪个类别,是关键字、标识符还是其他内容。词法分析器的主要任务之一是创建一对词元和记号,即收集所有的字符。
让我们来看一个例子:
if(y<= t)
y=y-3;
词元 记号
如果 `KEYWORD`,则 `y <= t`,并且 `y = IDENTIFIER _ 3`。词素和记号之间的关系如下图所示:
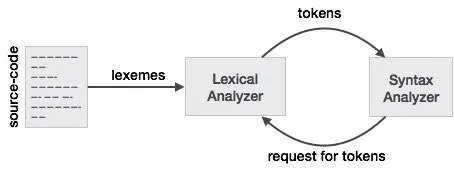
- coding_ninza
1
这个解释非常简单易懂!感谢分享。 - LomoY
8
LEXEME - 由PATTERN匹配的字符序列,形成TOKEN。
PATTERN - 定义TOKEN的一组规则。
TOKEN - 编程语言字符集上有意义的字符集合,例如:ID、常量、关键字、操作符、标点符号、文字字符串等。
- sravan kumar
7
词素 - 词素是源程序中与令牌模式匹配的字符序列,并被词法分析器识别为该令牌的实例。
令牌 - 令牌是由令牌名称和可选令牌值组成的一对。令牌名称是词法单元的类别。常见的令牌名称包括:
- 标识符: 程序员选择的名称
- 关键字: 编程语言中已有的名称
- 分隔符(也称为标点符号): 标点符号和成对的分隔符
- 运算符: 作用于参数并产生结果的符号
- 字面量: 数字、逻辑、文本、引用字面量
考虑下面这个用C语言编写的表达式:
sum = 3 + 2;
通过以下表格进行了标记和表示:
Lexeme Token category
------------------------------
sum | Identifier
= | Assignment operator
3 | Integer literal
+ | Addition operator
2 | Integer literal
; | End of statement
- Rajat Bhatt
7
a) Tokens是程序文本中组成实体的符号名称;例如,if关键字和任何标识符的id。这些组成了词法分析器的输出。
b) 模式是规则,指定输入中的字符序列何时构成一个标记;例如,i,f序列用于if标记,以字母开头的任何字母数字序列用于id标记。
c) Lexeme是与模式匹配的输入字符序列(因此构成标记的实例);例如,if与if的模式匹配,foo123bar与id的模式匹配。
- shasmoe
5
让我们来看看词法分析器(也称扫描器)的工作。
举个例子表达式:
输入:cout << 3+2+3;
扫描器执行的格式化:{cout}|空格|{<<}|空格|{3}{+}{2}{+}{3}{;}
这并不是实际的输出。
扫描器只是在源程序文本中反复寻找词素,直到输入用完为止。
词素是输入的子字符串,形成语法中存在的终端符号的有效字符串。每个词素都遵循一个模式,该模式在最后进行解释(读者可以跳过该部分)。
(一个重要规则是查找最长可能的前缀,形成一个有效的终端符号字符串,直到遇到下一个空格为止……在下面解释)
词素:
- cout
- <<
(虽然"<"也是一个有效的终端符号字符串,但上述提到的规则将选择词素“<<”的模式,以便生成扫描器返回的令牌)
- 3
-
- 2
- ;
令牌:每次扫描器找到(有效的)词素时,它会一次返回一个令牌(当解析器请求时)。扫描器创建一个符号表条目(具有主要是令牌类别和其他一些属性的属性),当它找到一个词素时,以便生成它的令牌。
'#'表示一个符号表条目。为了便于理解,我已经指出了上面列表中的词素编号,但在技术上它应该是符号表中记录的实际索引。
以下令牌按照指定顺序由扫描器向解析器返回上述示例。
<标识符,#1 >
<运算符,#2 >
<字面,#3 >
<运算符,#4 >
<字面,#5 >
<运算符,#4 >
<字面,#3 >
<标点符号,#6 >
如您所见,令牌和词素有所不同,令牌是一对,而词素是输入的子字符串。
而对于该对的第一个元素是令牌类别。
令牌类别列在下面:
- 关键字
- 标识符
- 文本常量
- 分隔符
- 运算符
还有一点:扫描器会检测到空格。它会忽略它们,因此不会为任何空格形成令牌。并非所有的分隔符都是空格;空格是扫描器用于其目的的一种分隔符。输入中的制表符、换行符、空格和转义字符在一起被称为空白分隔符。几个其他的分隔符是';', ',', ':'等,它们被广泛认为是形成令牌的词素。
这里返回的令牌总数为8。然而,对于词素只进行了6次符号表条目更新。总共有8个词素(请参阅词素的定义)。
您可以跳过这部分
模式是一个规则(比如正则表达式),用于检查一个由终端符组成的字符串是否有效。
如果输入的子串中只包含语法终端符,并且符合列出的任何一个模式指定的规则,则其被验证为词素,并且所选的模式将确定词素的类别;否则,由于不符合任何规则或存在语法中不存在的坏终端字符,将报告一个词法错误。
例如:
不存在的模式:在C++中,“99Id_Var”是受语法支持的终端符字符串,但它没有被任何模式识别出来,因此会报告一个词法错误。
不良输入字符:$,@以及Unicode字符可能不被某些编程语言支持作为有效字符。
- Mayank Narula
1
扫描器检测到空白字符。它会忽略它们,并且不为任何空白字符形成标记。这是一个很好的例子,说明标记并不总是以1:1方式表示输入,而是方便输入解析器的内容。 - Beni Cherniavsky-Paskin
4
Token(标记):包括关键词、标识符、标点符号以及多字符运算符等类型,是一种简单的标记。
Pattern(模式):从输入字符中形成标记的规则。
Lexeme(词元):源程序中与标记模式匹配的字符序列。基本上,它是标记的一个元素。
- mud1t
4
令牌(Token): 令牌是一组可以被视为单个逻辑实体的字符序列。典型的令牌包括:
1)标识符
2)关键字
3)运算符
4)特殊符号
5)常量
模式(Pattern): 一组字符串输入,产生相同的输出令牌。这组字符串由与令牌相关联的规则(称为模式)描述。
词素(Lexeme): 源程序中与令牌模式匹配的字符序列。
1)标识符
2)关键字
3)运算符
4)特殊符号
5)常量
模式(Pattern): 一组字符串输入,产生相同的输出令牌。这组字符串由与令牌相关联的规则(称为模式)描述。
词素(Lexeme): 源程序中与令牌模式匹配的字符序列。
- pradip
2
计算机科学研究人员,就像数学领域的人一样,喜欢创造“新”的术语。之前的回答都很好,但是在我看来,没有必要非常区分标记和词元。它们就像表示同一事物的两种方式。
词元是具体的——这里有一组字符;而标记则是抽象的——通常指词元的类型以及其语义值。希望我的见解能对您有所帮助。
词元是具体的——这里有一组字符;而标记则是抽象的——通常指词元的类型以及其语义值。希望我的见解能对您有所帮助。
- zell
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接