我正在尝试首次实现事件溯源/CQRS/DDD,主要是为了学习目的。其中有一个事件存储和消息队列(例如Apache Kafka)的概念,事件从事件存储流向Kafka Connect JDBC/Debezium CDC => Kafka。 我想知道为什么需要单独的事件存储,因为听起来Kafka本身具有其主要功能和日志压缩或配置日志保留以进行永久存储。我应该将我的事件存储在专用存储(如RDBMS)中以供Kafka使用,还是直接将它们馈送到Kafka?
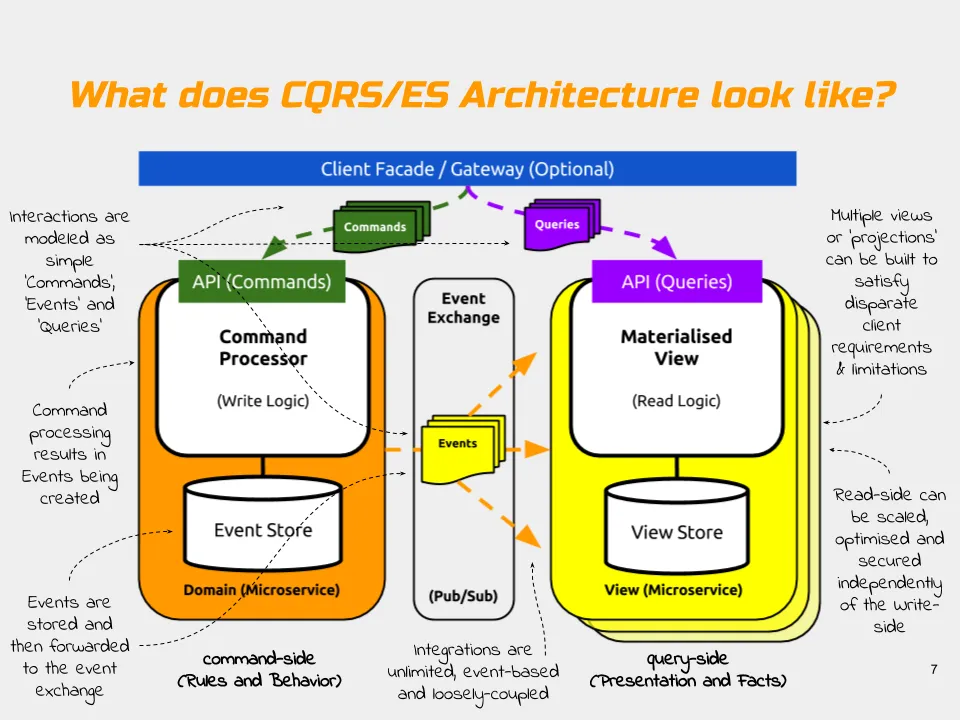
CQRS被称为DDDD... 分布式领域驱动设计。
领域驱动设计中的一个常见模式是拥有一个领域模型,以确保您持久存储中的数据完整性,也就是说,确保没有内部矛盾...
我想知道为什么需要单独的事件存储,因为它似乎可以通过Kafka本身的主要功能和日志压缩或配置日志保留实现其目的。
因此,如果我们想要一个没有内部矛盾的事件流,该怎么做呢?一种方法是确保只有一个进程有权限修改流。不幸的是,这会留下一个单点故障--进程死亡,一切都结束了。
另一方面,如果您有多个进程更新同一流,则存在并发写入、数据竞争和矛盾的风险,因为一个编写者可能还没有看到另一个编写者所做的内容。通过使用事务或比较和交换语义,我们可以使用RDBMS或事件存储来解决此问题;如果有并发修改,则拒绝尝试使用新事件扩展流。此外,由于其DDD遗产,持久存储通常被划分为许多非常细粒度的分区(也称为“聚合”)。一个购物车可能合理地有四个专门的流。唯一的另一个问题是处理故障(例如快照失败)。这可以在特定命令处理分区启动期间处理 - 它只需重播自上次快照成功以来的任何事件,并在恢复命令处理之前更新相应的快照。
Kafka Streams似乎具备使这个过程变得非常简单的功能-您可以将命令的KStream转换为KTable(包含聚合ID键入的快照),并拥有包含事件的KStream(和可能包含响应的另一个流)。 Kafka允许所有这些在事务中工作,因此不存在无法更新快照的风险。 它还处理将分区迁移到新服务器等问题(当这种情况发生时,会自动将快照KTable加载到本地RocksDB中)。理论上你可以使用Kafka作为事件存储,但正如许多人在上面提到的那样,你将有几个限制,其中最大的限制是只能使用Kafka中的偏移量来读取事件,而不能使用其他标准。
因此,有一些框架处理问题的Event Sourcing和CQRS部分。
Kafka只是工具链的一部分,它为您提供了重放事件和背压机制的功能,以保护您免受过载。
如果您想看看所有这些如何配合,请参阅我的博客。