我想准备一个包含连续、名义和序数特征的数据集以进行分类。我有一些解决方法,但我想知道是否有更好的方法可以使用scikit-learn的编码器?
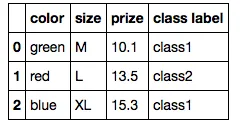
让我们考虑以下示例数据集:
import pandas as pd
df = pd.DataFrame([['green', 'M', 10.1, 'class1'], ['red', 'L', 13.5, 'class2'], ['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df
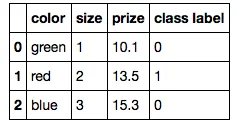
现在,类别标签可以通过标签编码器简单地转换(分类器忽略类别标签中的顺序)。
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
df['class label'] = class_le.fit_transform(df['class label'].values)
我会将序数特征列 size 转换如下:
size_mapping = {
'XL': 3,
'L': 2,
'M': 1}
df['size'] = df['size'].apply(lambda x: size_mapping[x])
df
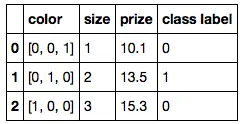
最后是序数color特性:
color_mapping = {
'green': [0,0,1],
'red': [0,1,0],
'blue': [1,0,0]}
df['color'] = df['color'].apply(lambda x: color_mapping[x])
df
y = df['class label'].values
X = df.iloc[:, :-1].values
X = np.apply_along_axis(func1d= lambda x: np.array(x[0] + list(x[1:])), axis=1, arr=X)
X
array([[ 0. , 0. , 1. , 1. , 10.1],
[ 0. , 1. , 0. , 2. , 13.5],
[ 1. , 0. , 0. , 3. , 15.3]])