这是一个链接列表,还是一个数组?我搜寻了一下,只发现有人在猜测。我的 C 语言知识不足以查看源代码。
Python的列表是如何实现的?
300
- Greg
1
根据文档(https://docs.python.org/3/faq/design.html#how-are-lists-implemented-in-cpython),Python列表不是链表。它们是可变大小的数组。它们也是可变的。我不确定它是否真正实现了逻辑和实际容量(这将使其成为完整的动态数组https://en.wikipedia.org/wiki/Dynamic_array)。因此,您可以说它是一种独特的数据结构。(尽管我真的相信它是一个动态数组) - Jdeep
10个回答
320
这段C代码实际上非常简单。展开一个宏并剪除一些不相关的注释后,基本结构在listobject.h中定义列表为:
typedef struct {
PyObject_HEAD
Py_ssize_t ob_size;
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number
* currently in use is ob_size.
* Invariants:
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
*/
Py_ssize_t allocated;
} PyListObject;
PyObject_HEAD 包含一个引用计数和类型标识符。因此,它是一个超配的向量/数组。当这种数组已经满了需要调整大小时,其代码位于 listobject.c 中。它实际上并没有将数组扩大一倍,而是通过分配内存来增长。
new_allocated = (newsize >> 3) + (newsize < 9 ? 3 : 6);
new_allocated += newsize;
每次增加的容量是newsize,其中newsize是请求的大小(不一定是allocated+1,因为你可以通过一次添加任意数量的元素而不是一个一个地append来extend)。
另请参见Python FAQ。
- Fred Foo
4
14因此,在 Python 中迭代列表跟链表一样慢,因为每个条目都只是一个指针,所以每个元素很可能会导致缓存未命中。 - Kr0e
19如果后续的元素实际上是相同的对象,那么不需要复制。但如果需要更小/更友好的缓存数据结构,则应优先使用
array模块或NumPy。 - Fred Foo6@Kr0e,我不会说遍历列表的速度比链表慢,但是遍历链表__值__的速度与链表一样慢,这是Fred提到的一个警告。例如,遍历列表将其复制到另一个列表中应该比链表更快。 - Dan Ganea
新的精确公式是 (x + (x >> 3) + 6) & ~3 (https://github.com/python/cpython/blob/main/Objects/listobject.c#L73C5-L73C73) - undefined
84
这是一个动态数组。实际证明:索引(当然有极小的差异(0.0013微秒!))花费相同的时间,无论索引是什么:
...>python -m timeit --setup="x = [None]*1000" "x[500]"
10000000 loops, best of 3: 0.0579 usec per loop
...>python -m timeit --setup="x = [None]*1000" "x[0]"
10000000 loops, best of 3: 0.0566 usec per loop
如果IronPython或Jython使用了链表,我会感到非常惊讶-它们将破坏许多广泛使用的库的性能,这些库建立在列表是动态数组的假设之上。
- user395760
11
4@Ralf: 我知道我的 CPU(大多数其他硬件也是如此)很老而且运行速度慢 - 但好的一面是,我可以假设对于我来说运行足够快的代码对所有用户来说都足够快 :D - user395760
2@John:啊,没错,发现了……已经修复并编辑了它(现在也使用len-1(999)作为第一个索引)。 - user395760
38表明这不是一个简单的链表实现,但并不能确定它是一个数组。 - Michael Mior
13您可以在这里阅读相关内容:http://docs.python.org/2/faq/design.html#how-are-lists-implemented。 - CCoder
11除了链表和数组,还有很多其他的数据结构。在选择数据结构时,计时对于决定使用哪种数据结构没有实际用处。 - Ross Hemsley
显示剩余6条评论
83
我建议阅读Laurent Luce's article "Python list implementation"。这篇文章对我很有帮助,因为作者解释了CPython如何实现列表,并使用优秀的图表进行说明。
 。
。
List object C structure
A list object in CPython is represented by the following C structure.
ob_itemis a list of pointers to the list elements. allocated is the number of slots allocated in memory.typedef struct { PyObject_VAR_HEAD PyObject **ob_item; Py_ssize_t allocated; } PyListObject;It is important to notice the difference between allocated slots and the size of the list. The size of a list is the same as
len(l). The number of allocated slots is what has been allocated in memory. Often, you will see that allocated can be greater than size. This is to avoid needing callingrealloceach time a new elements is appended to the list.
...
追加我们向列表中追加一个整数:l.append(1)。会发生什么?
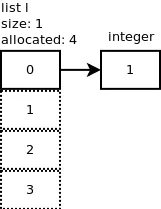
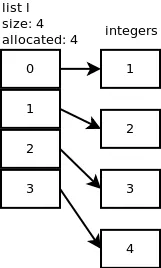
接下来,我们再添加一个元素:l.append(2)。调用了list_resize,n+1=2,但由于已分配的大小为4,因此无需再分配更多内存。当我们再添加两个整数时同样也是如此:l.append(3)、l.append(4)。以下图表显示目前为止的情况。
...
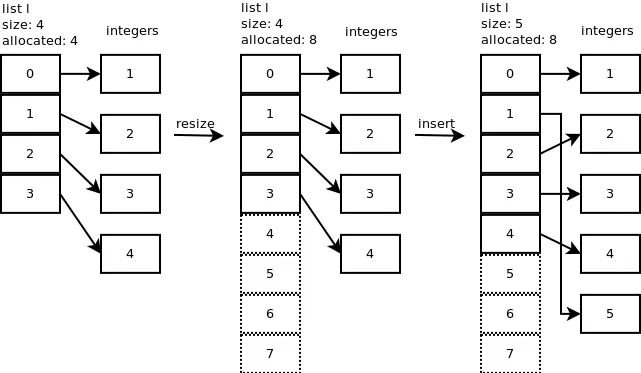
我来翻译一下。这段内容讲述了如何在编程中插入一个新的整数(5)到指定位置(1)。具体操作是使用代码l.insert(1,5),并且查看内部发生的事情。。
...
弹出当您弹出最后一个元素:l.pop(),会调用listpop()。在listpop()内部调用了list_resize,如果新的大小小于分配的一半,则会缩小列表。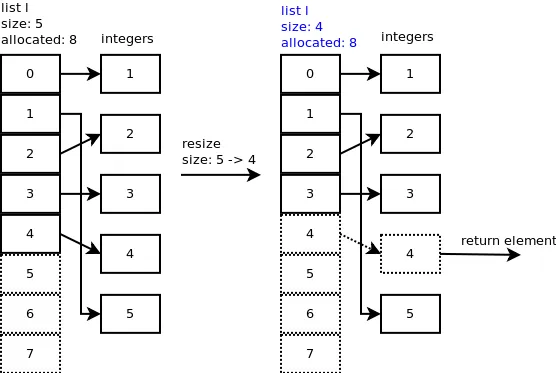
您可以观察到槽4仍然指向整数,但重要的是列表的大小现在为4。
让我们再弹出一个元素。在list_resize()中,size - 1 = 4-1 = 3小于分配的槽数的一半,因此将列表缩小到6个槽,并且列表的新大小现在为3。
您可以观察到槽3和4仍然指向某些整数,但重要的是列表的大小现在为3。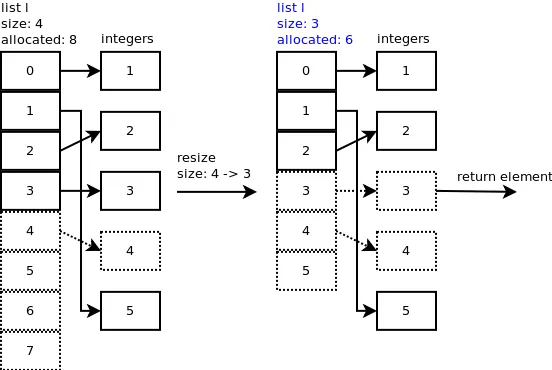
...
删除 Python列表对象有一种方法可以删除特定元素:
l.remove(5)。
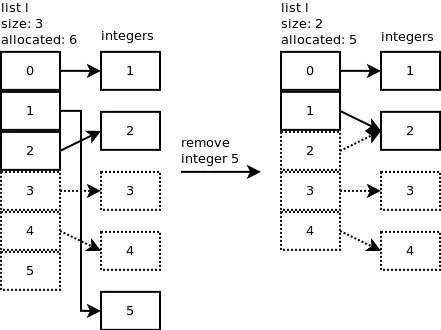
- Lesya
1
谢谢,我现在更理解列表的“链接部分”了。Python列表是一种“聚合”,而不是“组合”。我希望也有一个关于组合的列表。 - KRoy
49
- NullUserException
5
3Python解释器中实现列表为链表的情况是一种有效的Python语言实现,这取决于具体实现。换句话说,不能保证对列表进行O(1)随机访问。这难道不会使编写高效代码变得不可行,而必须依赖于实现细节吗? - sepp2k
3@sepp 我认为Python中的列表只是有序集合;其实现和/或性能要求并没有明确说明。 - NullUserException
7由于Python没有一个标准的或正式的规范(尽管有一些文档说“...保证...”),因此你不能像“这是由某张纸保证的”那样百分之百确定。但由于列表索引的
O(1) 是一个相当普遍和有效的假设,因此没有实现会冒险打破它。 - user395760@Paul 它没有说明列表的底层实现应该如何完成。 - NullUserException
1它只是没有指定事物的大O运行时间。语言语法规范并不一定意味着实现细节相同,它只是经常发生这种情况。 - Paul McMillan
41
在CPython中,列表是指针数组。Python的其他实现可能选择以不同的方式存储它们。
- Amber
5
如其他人所述,当列表很大时(可观的大),列表实现是通过分配一定量的空间来实现的。如果该空间应该填满,则分配更大的空间并复制元素。
要了解为什么该方法的平摊时间复杂度是O(1),不失一般性,假设我们插入了a = 2^n个元素,现在我们必须将表格扩大到2^(n+1)大小。这意味着我们目前正在执行2^(n+1)次操作。上一次复制,我们执行了2^n次操作。在此之前,我们进行了2^(n-1) ...一直到8、4、2、1次。现在,如果我们把它们加起来,我们得到1 + 2 + 4 + 8+…+2^(n+1) = 2^(n+2)-1 < 4*2^n = O(2^n)= O(a)总插入次数 (即O(1)平摊时间)。同时,需要注意的是,如果表允许删除,则表缩小必须以不同的因子进行(例如3x)。
要了解为什么该方法的平摊时间复杂度是O(1),不失一般性,假设我们插入了a = 2^n个元素,现在我们必须将表格扩大到2^(n+1)大小。这意味着我们目前正在执行2^(n+1)次操作。上一次复制,我们执行了2^n次操作。在此之前,我们进行了2^(n-1) ...一直到8、4、2、1次。现在,如果我们把它们加起来,我们得到1 + 2 + 4 + 8+…+2^(n+1) = 2^(n+2)-1 < 4*2^n = O(2^n)= O(a)总插入次数 (即O(1)平摊时间)。同时,需要注意的是,如果表允许删除,则表缩小必须以不同的因子进行(例如3x)。
- RussellStewart
2
据我所知,没有复制旧元素。会分配更多的空间,但新的空间不与已经被利用的空间相邻接,只有要插入的新元素会被复制到新的空间中。如果我说错了,请纠正我。 - Tushar Vazirani
@TusharVazirani 我认为CPython必须将旧元素复制到新分配的空间中。否则,Fred Foos在顶部回答中的
PyObject **ob_item;将无法工作,因为它必须指向旧元素的旧内存空间和新元素的新内存空间。 - Kilian Batzner1
Python中的列表类似于数组,可以存储多个值。列表是可变的,这意味着你可以更改它。你需要知道的更重要的事情是,当我们创建一个列表时,Python会自动为该列表变量创建一个引用ID。如果你通过分配其他变量来更改它,主列表将会改变。让我们尝试一个例子:
我们追加了
list_one = [1,2,3,4]
my_list = list_one
#my_list: [1,2,3,4]
my_list.append("new")
#my_list: [1,2,3,4,'new']
#list_one: [1,2,3,4,'new']
我们追加了
my_list,但是我们的主列表已经改变。这意味着该列表不是作为副本分配,而是作为其引用分配。- hasib
0
我发现这篇文章非常有帮助,可以理解如何使用Python代码实现列表。
class OhMyList:
def __init__(self):
self.length = 0
self.capacity = 8
self.array = (self.capacity * ctypes.py_object)()
def append(self, item):
if self.length == self.capacity:
self._resize(self.capacity*2)
self.array[self.length] = item
self.length += 1
def _resize(self, new_cap):
new_arr = (new_cap * ctypes.py_object)()
for idx in range(self.length):
new_arr[idx] = self.array[idx]
self.array = new_arr
self.capacity = new_cap
def __len__(self):
return self.length
def __getitem__(self, idx):
return self.array[idx]
- Arun
-4
在CPython中,列表被实现为动态数组,因此当我们添加元素时,不仅会添加一个宏,还会分配一些额外的空间,以便每次都不需要添加新的空间。
- gaurav
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接