我们尝试使用Intel CLFLUSH指令在Linux用户空间刷新进程的缓存内容。
我们创建了一个非常简单的C程序,首先访问一个大数组,然后调用CLFLUSH来刷新整个数组的虚拟地址空间。我们测量CLFLUSH刷新整个数组所需的延迟时间。程序中数组的大小是一个输入参数,我们将输入从1MB变化到40MB,步长为2MB。
我们理解CLFLUSH应该会刷新缓存中的内容。因此,我们期望看到刷出整个数组的延迟随着数组大小的增加呈线性增长,而在数组大小大于20MB(我们程序的LLC大小)后,延迟应该停止增加。
但是,实验结果非常出人意料,如图所示。当数组大小大于20MB时,延迟不会停止增加。
我们想知道如果地址不在缓存中,CLFLUSH是否可能在刷新地址之前将其带入缓存?我们还尝试在Intel软件开发手册中搜索,没有找到任何关于CLFLUSH如何处理不在缓存中的地址的说明。
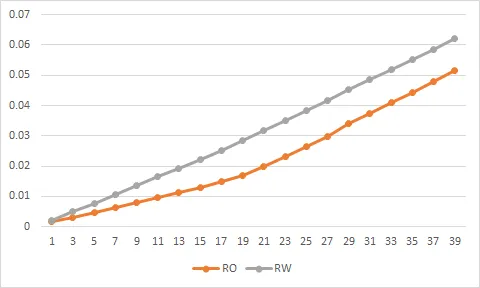
下面是我们用来绘制图表的数据。第一列是数组的大小(KB),第二列是刷出整个数组所需的延迟时间(秒)。
任何建议/意见都将不胜感激。
[修改]
以前的代码是不必要的。虽然性能类似,但CLFLUSH可以在用户空间更轻松地完成。因此,我删除了混乱的代码以避免混淆。
SCENARIO=Read Only
1024,.00158601000000000000
3072,.00299244000000000000
5120,.00464945000000000000
7168,.00630479000000000000
9216,.00796194000000000000
11264,.00961576000000000000
13312,.01126760000000000000
15360,.01300500000000000000
17408,.01480760000000000000
19456,.01696180000000000000
21504,.01968410000000000000
23552,.02300760000000000000
25600,.02634970000000000000
27648,.02990350000000000000
29696,.03403090000000000000
31744,.03749210000000000000
33792,.04092470000000000000
35840,.04438390000000000000
37888,.04780050000000000000
39936,.05163220000000000000
SCENARIO=Read and Write
1024,.00200558000000000000
3072,.00488687000000000000
5120,.00775943000000000000
7168,.01064760000000000000
9216,.01352920000000000000
11264,.01641430000000000000
13312,.01929260000000000000
15360,.02217750000000000000
17408,.02516330000000000000
19456,.02837180000000000000
21504,.03183180000000000000
23552,.03509240000000000000
25600,.03845220000000000000
27648,.04178440000000000000
29696,.04519920000000000000
31744,.04858340000000000000
33792,.05197220000000000000
35840,.05526950000000000000
37888,.05865630000000000000
39936,.06202170000000000000
clflush。可能即使实际上没有任何操作,它也会在uops方面产生显着的成本或有限的吞吐量。您应该查看perf计数器(使用perf)。ocperf.py是一个很好的perf包装器,它为uop计数器添加了符号名称。 - Peter Cordesclflush_cache_range已经针对Skylake进行了优化,并且在clflush循环之前/之后包含了内存屏障,因为它使用了一个函数,如果CPU支持clflushopt,则将其热补丁到clflushopt。内存屏障不是免费的,也许你看到的一些成本就是来自这里?我猜你在用户空间也得到了类似的结果。如果是这样,内存屏障的成本就无法解释了,因为你在用户空间版本中没有使用MFENCE。 - Peter Cordesclflush。这样更容易进行分析,并且可以轻松地对整个数组进行操作。如果我们不试图刷新进程的代码,它会消除一整层复杂性。我不确定TLB在系统调用上下文中的工作原理。内核是否使用与用户空间相同的页表来访问用户内存?我的猜测是“是”,但如果不是,在内核中执行将产生额外的TLB缺失。 - Peter Cordes