这是一个关于此问题的后续问题。
所以我从“编程访问”角度不断探索现代分析器的能力,并发现了一些超出我的理解范围的东西。
这次我偶然发现了JProfiler中的“分配调用树”功能:
当然,我的问题不是关于JProfiler的实现细节,我知道它是一个商业工具,有着紧密的代码等等,而是关于如何检索这种信息的一般理解。
我的初步猜测是它以某种方式“检测”已加载的类文件,以“拦截”为这些对象分配的每个操作(采样率不会太慢),但是接下来呢?它是否调用像
另一方面,它处于“采样模式”(与仪器相对)+存在性能问题-这听起来对我来说非常昂贵(即不应在生产中使用),但我可能错了,因此任何建议都将不胜感激。
所以我从“编程访问”角度不断探索现代分析器的能力,并发现了一些超出我的理解范围的东西。
这次我偶然发现了JProfiler中的“分配调用树”功能:
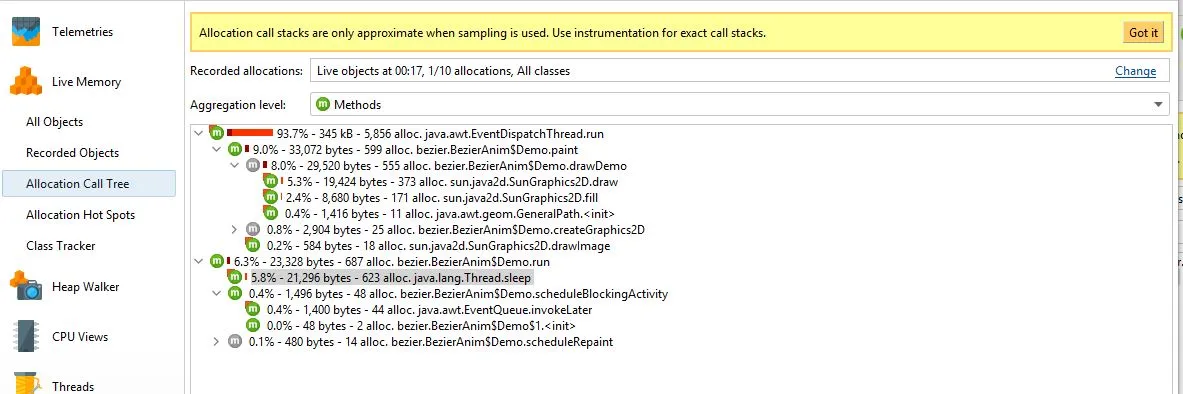
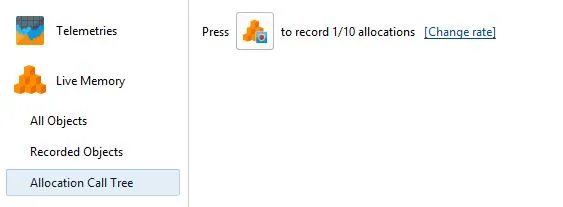
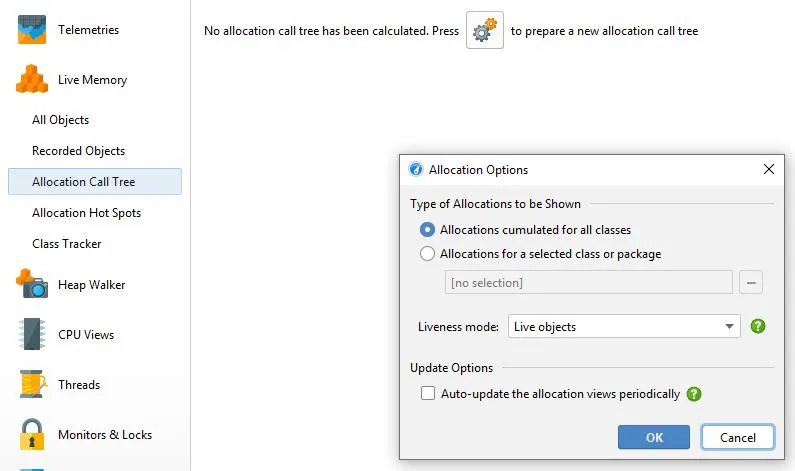
我发现要获取这种信息,首先需要使用默认1/10的采样率触发分配,并指定(最好是)记录已分配类的包。
步骤1
当然,我的问题不是关于JProfiler的实现细节,我知道它是一个商业工具,有着紧密的代码等等,而是关于如何检索这种信息的一般理解。
我的初步猜测是它以某种方式“检测”已加载的类文件,以“拦截”为这些对象分配的每个操作(采样率不会太慢),但是接下来呢?它是否调用像
Thread.currentThread().getStackTrace()这样的东西,并记录导致分配的实际堆栈跟踪?另一方面,它处于“采样模式”(与仪器相对)+存在性能问题-这听起来对我来说非常昂贵(即不应在生产中使用),但我可能错了,因此任何建议都将不胜感激。