EMA(指数移动平均线)的一般公式:
EMA(xn) = α * xn + (1 - α) * EMA(xn-1)
其中:
xn = 价格 α = 0.5 -- 给定3天SMA
以下递归CTE可以完成此任务:
WITH recursive
ewma_3 (DATE, PRICE, EMA_3, rn)
AS (
-- Anchor
-- Feed SMA_3 to recursive CTE
SELECT rows."DATE", rows."PRICE", sma.sma AS ewma, rows.rn
FROM (
SELECT "DATE", "PRICE", ROW_NUMBER() OVER(ORDER BY "DATE") rn
FROM PRICE_TBL
) rows
JOIN (
SELECT "DATE",
ROUND(AVG("PRICE"::numeric)
OVER(ORDER BY "DATE" ROWS BETWEEN 2 PRECEDING AND CURRENT ROW), 6) AS sma
FROM PRICE_TBL
) sma ON sma."DATE" = rows."DATE"
WHERE rows.rn = 3
UNION ALL
-- Recursive Member
SELECT rows."DATE", rows."PRICE"
-- Calculate EMA_3 below
,ROUND(((rows."PRICE"::numeric * 0.5) +
(ewma.EMA_3 * (1 - 0.5))), 6) AS ewma
, rows.rn
FROM ewma_3 ewma
JOIN (
SELECT "DATE", "PRICE", ROW_NUMBER() OVER(ORDER BY "DATE") rn
FROM PRICE_TBL
) rows ON ewma.rn + 1 = rows.rn
WHERE rows.rn > 3
)
SELECT ewma_3.rn AS "ID", DATE, PRICE, EMA_3
FROM ewma_3
;
这更多是关于效率和速度的问题。一个9852行的样本集需要 11秒631毫秒 才能完成。
我读到聚合器会保留最后计算元素的结果,如果是这样:
- 有人可以提供一个使用聚合函数的工作示例吗?
我也乐意听取任何改进CTE的建议,但我认为聚合会更快。我也知道这是一个老话题,但我对posgres还比较新,所以非常感谢任何帮助。谢谢!
更新
样本数据:
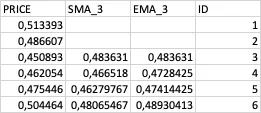
在7天内我的CTE返回以下结果(不包含日期):
ID PRICE EMA_7
--+----------+-----------
7 0.529018 0.4888393
8 0.551339 0.5044642
9 0.580357 0.5234374
10 0.633929 0.5510603
11 0.642857 0.5740095
12 0.627232 0.5873151
尽管@GordonLinoff提供的递归CTE更快,但 聚合器(aggregated func) 对于速度最优。我尝试了这个,但是报错:
错误:函数ema(numeric,numeric)不存在。
显然,没有任何函数与给定名称和参数类型匹配。需要明确的类型转换吗?毫无头绪。