我很好奇用G1和Epsilon测量JDK 13中分配内存所花费的时间。我观察到的结果出乎意料,我想了解其中的原因。最终,我希望了解如何使Epsilon的使用比G1更具性能(或如果不可能,则为什么不行)。
我编写了一个小测试,重复地分配内存。根据命令行输入,它要么:
- 创建1,024个新的1 MB数组;或者
- 创建1,024个新的1 MB数组,测量分配周围的时间,并打印出每次分配的经过时间。这不仅仅是测量分配本身,还包括在
System.nanoTime()两次调用之间发生的任何其他事情的经过时间——尽管这似乎是一个有用的信号。
以下是代码:
public static void main(String[] args) {
if (args[0].equals("repeatedAllocations")) {
repeatedAllocations();
} else if (args[0].equals("repeatedAllocationsWithTimingAndOutput")) {
repeatedAllocationsWithTimingAndOutput();
}
}
private static void repeatedAllocations() {
for (int i = 0; i < 1024; i++) {
byte[] array = new byte[1048576]; // allocate new 1MB array
}
}
private static void repeatedAllocationsWithTimingAndOutput() {
for (int i = 0; i < 1024; i++) {
long start = System.nanoTime();
byte[] array = new byte[1048576]; // allocate new 1MB array
long end = System.nanoTime();
System.out.println((end - start));
}
}
这是我正在使用的JDK版本信息:
$ java -version
openjdk version "13-ea" 2019-09-17
OpenJDK Runtime Environment (build 13-ea+22)
OpenJDK 64-Bit Server VM (build 13-ea+22, mixed mode, sharing)
这是我运行程序的不同方式:
- 仅使用G1进行分配:
$ time java -XX:+UseG1GC Scratch repeatedAllocations - 仅进行分配,使用Epsilon:
$ time java -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC Scratch repeatedAllocations - 使用G1进行分配、计时和输出:
$ time java -XX:+UseG1GC Scratch repeatedAllocationsWithTimingAndOutput - 进行分配、计时和输出,使用Epsilon:
time java -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC Scratch repeatedAllocationsWithTimingAndOutput
以下是仅使用G1进行分配时的一些计时信息:
$ time java -XX:+UseG1GC Scratch repeatedAllocations
real 0m0.280s
user 0m0.404s
sys 0m0.081s
$ time java -XX:+UseG1GC Scratch repeatedAllocations
real 0m0.293s
user 0m0.415s
sys 0m0.080s
$ time java -XX:+UseG1GC Scratch repeatedAllocations
real 0m0.295s
user 0m0.422s
sys 0m0.080s
$ time java -XX:+UseG1GC Scratch repeatedAllocations
real 0m0.296s
user 0m0.422s
sys 0m0.079s
以下是仅使用分配运行 Epsilon 的一些时间:
$ time java -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC Scratch repeatedAllocations
real 0m0.665s
user 0m0.314s
sys 0m0.373s
$ time java -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC Scratch repeatedAllocations
real 0m0.652s
user 0m0.313s
sys 0m0.354s
$ time java -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC Scratch repeatedAllocations
real 0m0.659s
user 0m0.314s
sys 0m0.362s
$ time java -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC Scratch repeatedAllocations
real 0m0.665s
user 0m0.320s
sys 0m0.367s
使用G1时,无论是否启用时间和输出,速度都比Epsilon更快。作为额外的衡量标准,使用repeatedAllocationsWithTimingAndOutput中的计时数字,当使用Epsilon时平均分配时间较长。具体而言,其中一个本地运行显示G1GC平均每次分配需要227,218纳秒,而Epsilon平均需要521,217纳秒(我捕获了输出数字,将其粘贴到电子表格中,并对每组数字使用了average功能)。
我的期望是Epsilon测试会明显更快,但在实践中,我看到的速度要慢大约两倍。G1的最大分配时间确实更高,但仅间歇性地 - 大多数G1分配速度要比Epsilon慢得多,几乎慢了一个数量级。
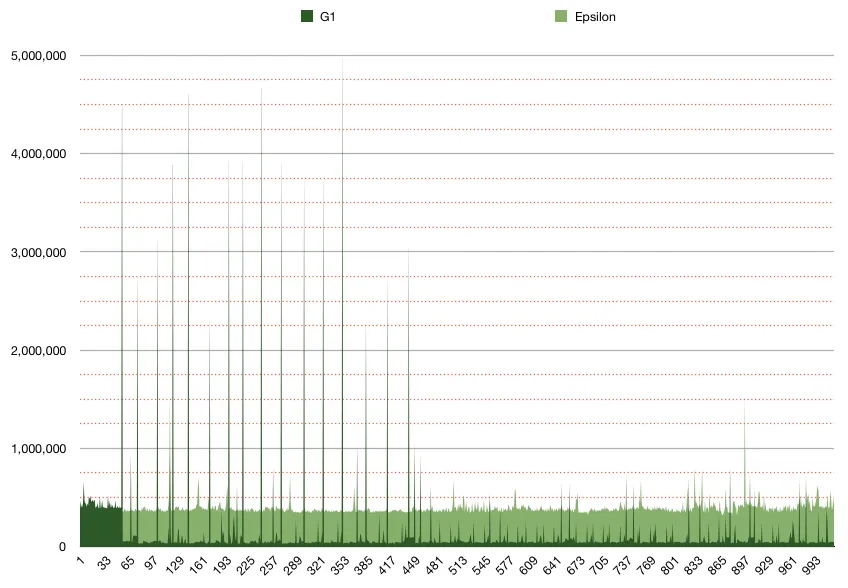
下面是运行repeatedAllocationsWithTimingAndOutput() 1024次的结果绘图,其中深绿色表示G1;浅绿色表示Epsilon;Y轴是“每个分配的纳秒数”;Y轴小网格线每250,000个纳秒。它显示Epsilon分配时间非常一致,每次大约在300-400k纳秒左右。它还显示G1的时间大部分时间明显更快,但也时断时续地比Epsilon慢了大约10倍。我认为这可能归因于垃圾收集器运行,这是合理和正常的,但似乎也是否定了G1聪明地知道它不需要分配任何新内存的想法。
array没有被使用,因此它变得可被垃圾收集器回收,然后旧的内存就被重用了,而Epsilon可能需要向操作系统请求更多的内存。 简而言之:这个测试没有显示任何东西。 - Johannes Kuhn