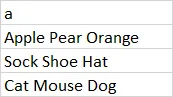
df1
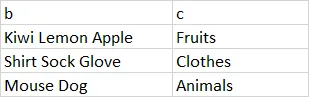
df2
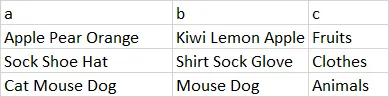
df3
library(dplyr)
library(fuzzyjoin)
df1 <- tibble(a =c("Apple Pear Orange", "Sock Shoe Hat", "Cat Mouse Dog"))
df2 <- tibble(b =c("Kiwi Lemon Apple", "Shirt Sock Glove", "Mouse Dog"),
c = c("Fruit", "Clothes", "Animals"))
# Appends 'Animals'
df3 <- regex_left_join(df1,df2, c("a" = "b"))
# Appends Nothing
df3 <- stringdist_left_join(df1, df2, by = c("a" = "b"), max_dist = 3, method = "lcs")
我想将df2的c列使用字符串'Apple'、'Sock'和'Mouse Dog'添加到df1中。
我尝试使用regex_join和fuzzyjoin,但似乎字符串的顺序很重要,而且似乎找不到解决方法。