问题。
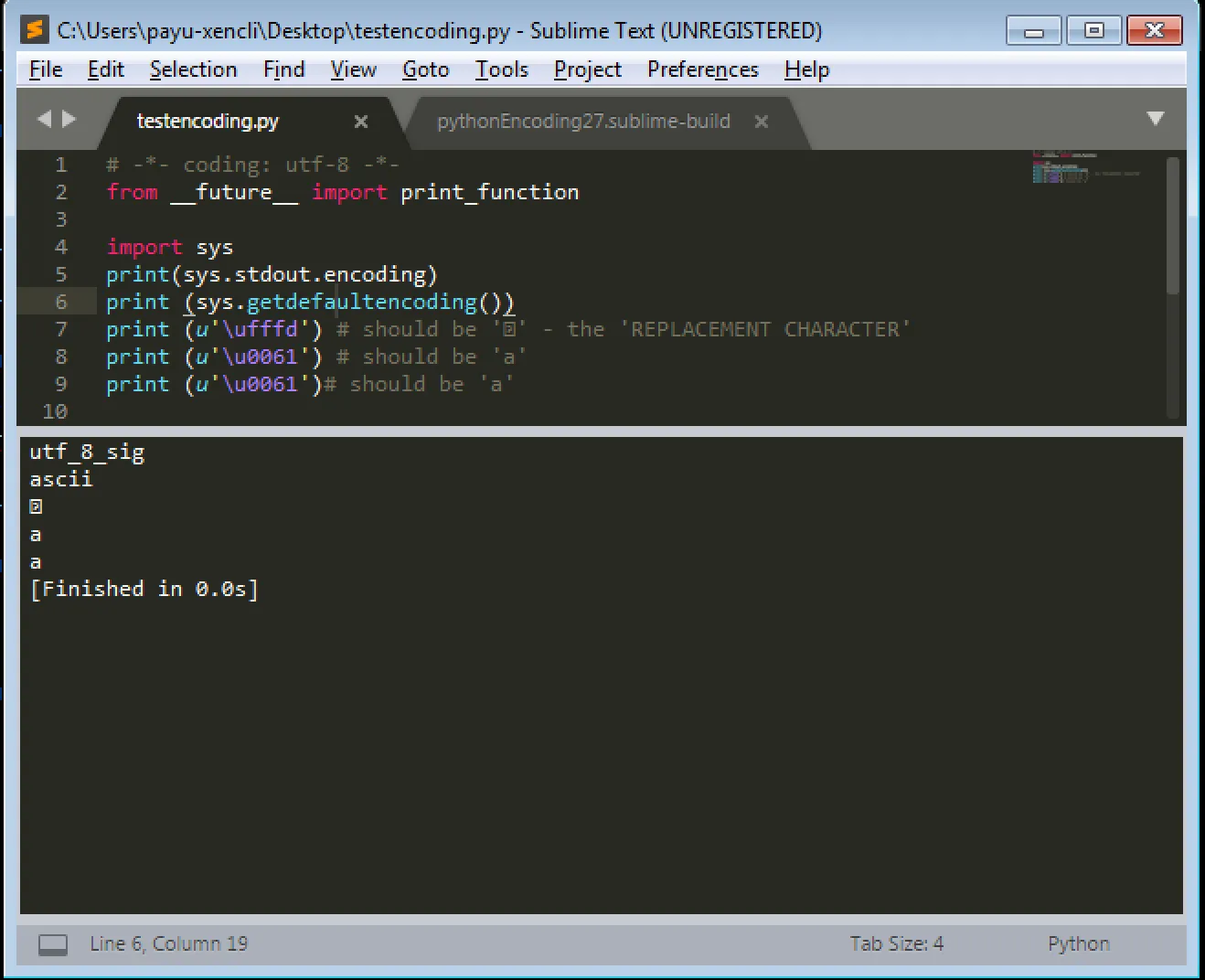
我正在使用在Sublime Text 3上构建的Python 2.7,并且在打印输出时遇到了问题。
在某些情况下,对于'\uFFFD' - 'REPLACEMENT CHARACTER',我得到了一个相当令人困惑的输出。
例如:
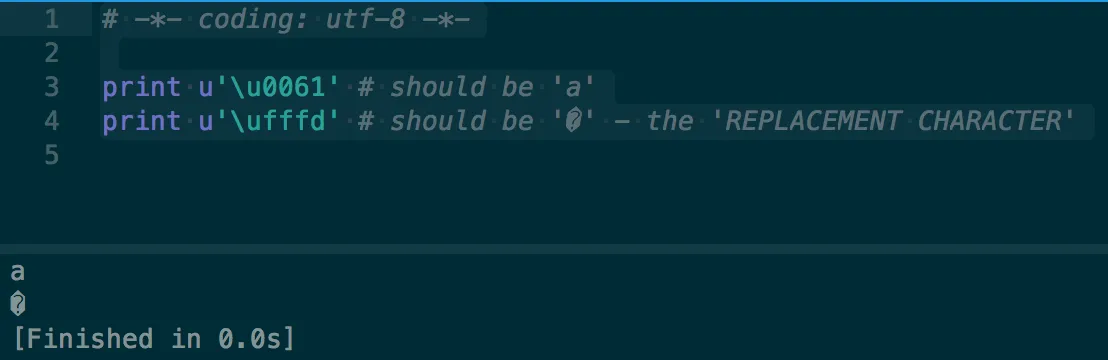
print u'\ufffd' # should be '�' - the 'REPLACEMENT CHARACTER'
print u'\u0061' # should be 'a'
-----------------------------------------------------
[Finished in 0.1s]
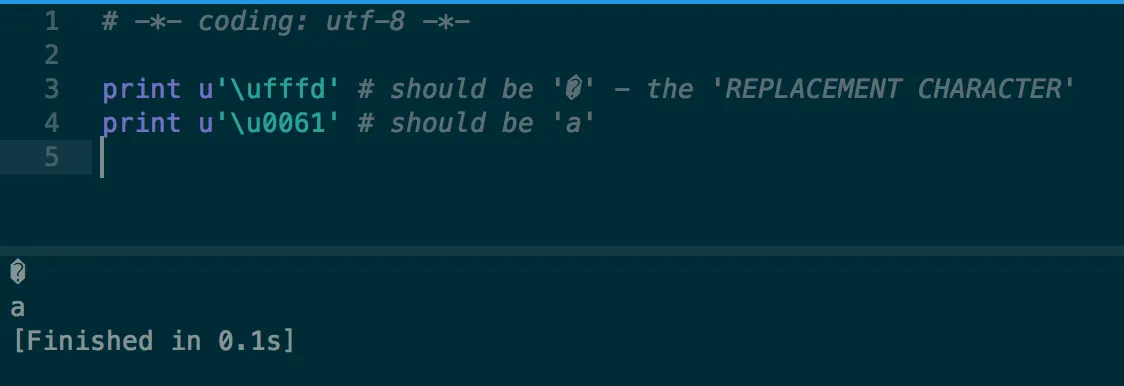
在顺序反转后:
print u'\u0061'
print u'\ufffd'
-----------------------------------------------------
a
�
[Finished in 0.1s]
所以,Sublime可以打印出“�”字符,但不知何故在第一种情况下无法打印出来。
而输出结果与语句顺序的依赖关系似乎非常奇怪。
替换字符的问题通常会导致打印行为非常不可预测。
例如,我想使用错误替换打印解码后的字节:
cp1251_bytes = '\xe4\xe0' # 'да' in cp1251
print cp1251_bytes.decode('utf-8', errors='replace')
-----------------------------------------------------
��
[Finished in 0.1s]
让我们替换字节:
cp1251_bytes = '\xed\xe5\xf2' # 'нет' in cp1251
print cp1251_bytes.decode('utf-8', errors='replace')
-----------------------------------------------------
[Finished in 0.1s]
并添加一个额外的打印语句:
cp1251_bytes = '\xed\xe5\xf2' # 'нет' in cp1251
print cp1251_bytes.decode('cp1251')
print cp1251_bytes.decode('utf-8', errors='replace')
-----------------------------------------------------
нет
���
[Finished in 0.1s]
以下是实施其他测试用例的示例:
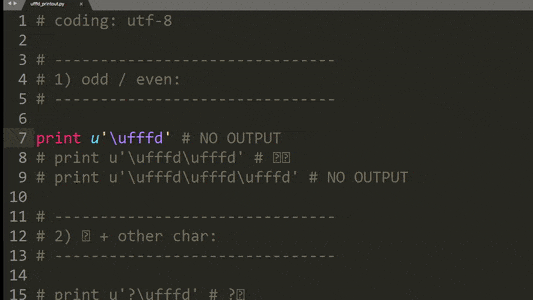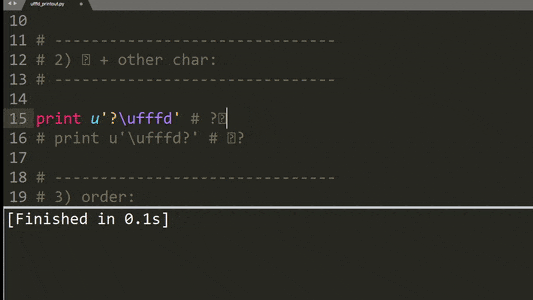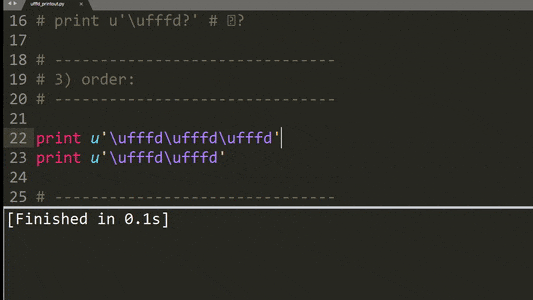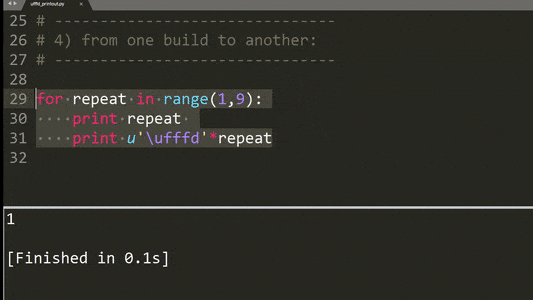
总结一下,描述的打印行为有以下模式:
'\ufffd'字符的奇偶数
我的问题:
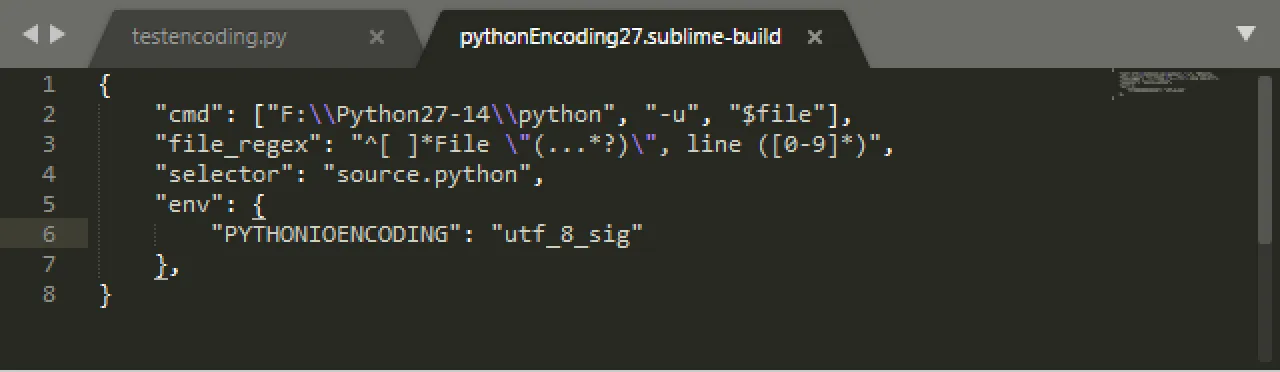
我的Python 2.7 sublime-build文件:
{
"cmd": ["C:\\_Anaconda3\\envs\\python27\\python", "-u", "$file"],
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)",
"selector": "source.python",
"env": {"PYTHONIOENCODING": "utf-8"}
}
如果单独安装了Python 2.7而不是Anaconda,则行为完全相同。