你正在打印
马拉雅拉姆Unicode码点,其中使用了很多
元音符号来修改前一个字形。这些元音符号码点本身并不形成新的字母,而马拉雅拉姆语在终端中产生的输出宽度与ASCII字母不同。
例如,在你的第一个字符串中以
U+0D38 MALAYALAM LETTER SA和
U+0D3F MALAYALAM VOWEL SIGN I开头。第一个字符
letter SA在屏幕上占据了一个完整的位置,但第二个字符,
vowel sign I,当它在SA之前时,会改变字母的打印方式。请注意,打印了2个码点后,只有
一个可见的字形:
>>> print u'\u0d38'
സ
>>> print u'\u0d3f'
ി
>>> print u'\u0d38\u0d3f'
സി
马拉雅拉姆语的代码点宽度也不同;如果将ASCII字母添加到SA和元音符号I下面,分别和组合起来,就像这样:
>>> print u'\u0d38\nA..\n\u0d3f\nB..\n\u0d38\u0d3f\nAB.'
സ
A..
ി
B..
സി
AB.
请注意
സ比
A宽(大约宽2.5倍),而
സി几乎与固定宽度的3个ASCII代码点一样宽!然而,并非所有马拉雅拉姆字母都是这么宽。在第一个示例中,下一个字母是
U+0D1F MALAYALAM LETTER TTA,它要窄得多:
>>> print u'\u0d38\nA..\n\u0d1f\nB..'
സ
A..
ട
B..
在实践中,我希望这种差异并不重要,而是将代码点组合起来,以便输出的宽度大致相同。
此外,马拉雅拉姆语还有其他的组合字符;您的第一个字符串包含
U+0D4D MALAYALAM SIGN VIRAMA,它已经与前面的字母TTA组合在一起。
当与前面的字母组合时,变音符会对打印宽度造成混乱:
>>> print u'\u0d1f\nA..\n\u0d4d\nB..\n\u0d1f\u0d4d\nAB.'
ട
A..
്
B..
ട്
AB.
字母TTA的宽度与ASCII字母一样,添加维拉玛符号后,宽度实际上并没有改变。
您可以通过查看代码点Unicode通用类别来近似大小。 unicodedata.category()函数会将类别作为字符串返回:
>>> import unicodedata
>>> unicodedata.category(u'\u0d38')
'Lo'
>>> unicodedata.category(u'\u0d3f')
'Mc'
>>> unicodedata.category(u'\u0d4d')
'Mn'
字母SA是Lo(Letter, other),元音符号是Mc(Mark, spacing combining),维拉马符号是Mn(Mark, nonspacing)。
>>> categories = {}
>>> for c in a[0]:
... cat = unicodedata.category(c)
... categories[cat] = categories.get(cat, 0) + 1
...
>>> categories
{'Lo': 4, 'Mn': 1, 'Mc': 4, 'Zs': 1}
对于第一个字符串,有4个字母、4个组合标记和一个元音符号。类别
Zs(分隔符,空格)用于ASCII空格字符
' '。
如果我们跳过
Mc和
Mn字符,能否更好地预测它们的宽度?字符串
a[0]的宽度将为5个字符(4次
Lo和1个空格)。
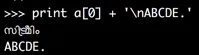
>>> print a[0] + '\nABCDE.'
സി ട്രീമിം
ABCDE.
在浏览器中,这看起来不够清晰,但在我的iTerm终端窗口中,它看起来像这样:
为了让你的行排列整齐,你需要计算正确的宽度来为字符串添加额外的空格,以弥补显示宽度和代码点数之间的差异。
import unicodedata
def malayalam_width(s):
return sum(1 for c in s if unicodedata.category(c)[0] != 'M')
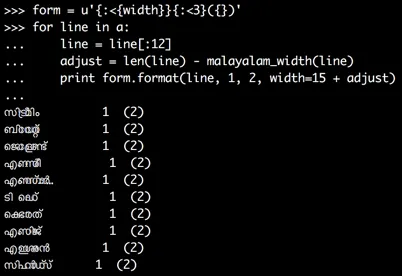
form = u'{:<{width}}{:<3}({})'
for line in a:
line = line[:12]
adjust = len(line) - malayalam_width(line)
print form.format(line, 1, 2, width=15 + adjust)
这已经大大提高了输出的质量:
似乎那些更宽的字母确实起到了作用。你需要手动添加更多的宽度来获得更好的结果;通过将字母映射到调整后的宽度,你可以再次使其对齐得更好一些。但是,码点宽度由所使用的字体设置,我不确定是否容易找到一种字体,它对所有马拉雅拉姆字母使用相等的宽度。
我发现使用制表位要容易得多,只需使用
form = u'{:<{width}}\t{:<3}({})'
for line in a:
line = line[:12]
adjust = len(line) - malayalam_width(line)
print form.format(line, 1, 2, width=12 + adjust)
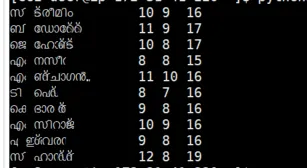
现在数字排列正确:
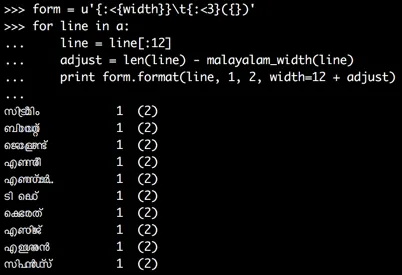
你确实需要不断调整宽度;否则,一半的时间你会停在错误的制表位。
注意:我对马拉雅拉姆文并不熟悉,我肯定会忽略各种字母、元音符号和变音符号之间相互作用的微妙差别。对于熟悉该脚本和Unicode代码点的人来说,可能能够提供比我这里介绍的更好的宽度近似函数。
我还忽略了你最后一个字符串中目前存在的2个U+200C零宽度非连接器代码点;你可能需要从数据中删除它们。正如它的名字所示,它也没有宽度。