tl;dr: 最快的方法取决于数组的大小。对于小于2
14的数组,下面的方法3 (
accumarray) 更快。对于大于该大小的数组,下面的方法2 (
histcounts) 更好。
更新:我还使用了2016b引入的
implicit broadcasting进行了测试,结果几乎与
bsxfun方法相同,在该方法中没有显着差异(相对于其他方法)。
让我们看看有哪些可用的方法来执行此任务。对于以下示例,我们将假设
X具有
n个元素,从1到
n,我们感兴趣的数组是
M,它是一个大小可能变化的列数组。我们的结果向量将是
spp1,其中
spp(k)是
M中
k的数量。尽管我在这里写关于
X,但在下面的代码中没有明确的实现,我只定义
n = 500,并且
X隐式地为
1:500。
朴素的for循环
解决此任务最简单和直接的方法是使用一个
for循环迭代
X中的元素,并计算等于它的
M中的元素数量:
function spp = loop(M,n)
spp = zeros(n,1);
for k = 1:size(spp,1);
spp(k) = sum(M==k);
end
end
当然,这样做并不聪明,特别是当只有来自X的少量元素填充M时,因此我们最好先寻找那些已经在M中的元素:
function spp = uloop(M,n)
u = unique(M);
spp = zeros(n,1);
for k = u(u>0).';
spp(k) = sum(M==k);
end
end
通常,在MATLAB中,尽可能利用内置函数是可取的,因为大多数情况下它们更快。我想到了5个选项来实现这一点:
1. 函数
tabulate
函数
tabulate返回一个非常方便的频率表,乍一看似乎是这个任务的完美解决方案:
function tab = tabi(M)
tab = tabulate(M);
if tab(1)==0
tab(1,:) = [];
end
end
唯一需要修复的是,如果表格中计数了
0元素(可能
M中没有零),则需要删除表格的第一行。
2.函数
histcounts。另一个可以很容易地根据我们的需求进行调整的选项是
histcounts:
function spp = histci(M,n)
spp = histcounts(M,1:n+1);
end
在这里,为了分别计算1到
n之间的所有不同元素,我们将边界定义为
1:n+1,因此
X中的每个元素都有自己的箱子。我们也可以编写
histcounts(M(M>0),'BinMethod','integers'),但我已经测试过它,它需要更多时间(尽管它使函数独立于
n)。
3. 函数
accumarray
接下来我要介绍的选项是使用函数
accumarray:
function spp = accumi(M)
spp = accumarray(M(M>0),1);
end
在这里,我们将函数
M(M>0)作为输入,以跳过零,并使用
1作为
vals输入来计算所有唯一元素的数量。
我们甚至可以使用二进制运算符
@eq(即
==)来查找每种类型的所有元素:
function spp = bsxi(M,n)
spp = bsxfun(@eq,M,1:n);
spp = sum(spp,1);
end
如果我们将第一个输入
M和第二个
1:n放在不同的维度中,那么一个是列向量,另一个是行向量,然后函数将比较
M中的每个元素与
1:n中的每个元素,并创建一个
length(M)-by-
n逻辑矩阵,我们可以对其进行求和以获得所需的结果。
另一种选项类似于
bsxfun,即使用
ndgrid函数显式创建所有可能性的两个矩阵:
function spp = gridi(M,n)
[Mx,nx] = ndgrid(M,1:n);
spp = sum(Mx==nx);
end
然后我们将它们进行比较并在列上求和,以得到最终结果。
基准测试
我进行了一项小测试,以找出所有上述方法中最快的方法,我对所有测试定义了 n = 500。对于某些方法(特别是天真的 for),n 对执行时间有很大的影响,但这不是问题,因为我们想要针对给定的 n 进行测试。
以下是测试结果: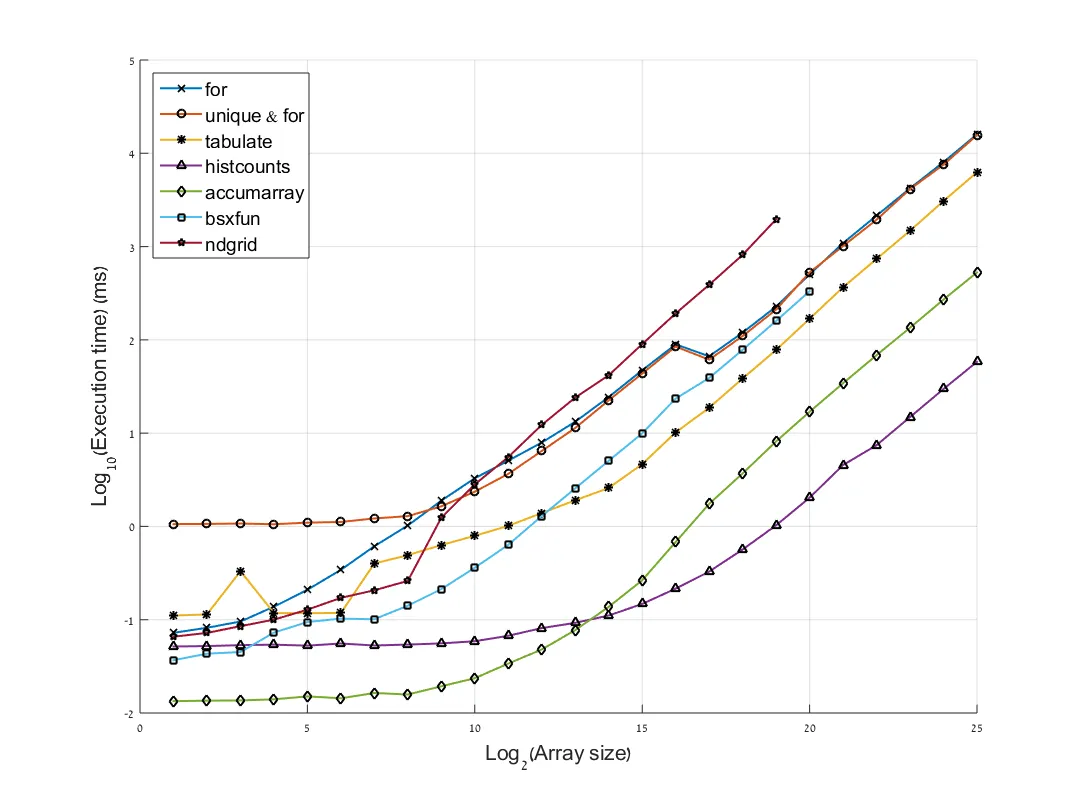
我们可以注意到几件事:
- 有趣的是,最快的方法发生了转变。对于小于214的数组来说,
accumarray是最快的。对于大于214的数组,histcounts是最快的。
- 如预期的那样,在两个版本中,朴素的
for循环都是最慢的,但对于小于28的数组,“unique & for”选项更慢。在大于211 的数组中,ndgrid成为最慢的,这可能是因为需要在内存中存储非常大的矩阵。
tabulate在小于29的大小的数组上工作的方法存在一些不规则性。在我进行的所有试验中,这个结果是一致的(模式略有变化)。
(由于在更高的值上会导致计算机卡顿,并且趋势已经非常明显),所以bsxfun和ndgrid曲线被截断了)
另外,请注意y轴为log10,因此单位减少(比如对于大小为219的数组,在accumarray和histcounts之间),意味着操作速度快了10倍。
欢迎在评论中提出改进此测试的建议,如果您有另一种概念上不同的方法,请建议为答案。
代码
这里是所有函数包装在一个计时函数中:
function out = timing_hist(N,n)
M = randi([0 n],N,1);
func_times = {'for','unique & for','tabulate','histcounts','accumarray','bsxfun','ndgrid';
timeit(@() loop(M,n)),...
timeit(@() uloop(M,n)),...
timeit(@() tabi(M)),...
timeit(@() histci(M,n)),...
timeit(@() accumi(M)),...
timeit(@() bsxi(M,n)),...
timeit(@() gridi(M,n))};
out = cell2mat(func_times(2,:));
end
function spp = loop(M,n)
spp = zeros(n,1);
for k = 1:size(spp,1);
spp(k) = sum(M==k);
end
end
function spp = uloop(M,n)
u = unique(M);
spp = zeros(n,1);
for k = u(u>0).';
spp(k) = sum(M==k);
end
end
function tab = tabi(M)
tab = tabulate(M);
if tab(1)==0
tab(1,:) = [];
end
end
function spp = histci(M,n)
spp = histcounts(M,1:n+1);
end
function spp = accumi(M)
spp = accumarray(M(M>0),1);
end
function spp = bsxi(M,n)
spp = bsxfun(@eq,M,1:n);
spp = sum(spp,1);
end
function spp = gridi(M,n)
[Mx,nx] = ndgrid(M,1:n);
spp = sum(Mx==nx);
end
这是运行此代码并生成图形的脚本:
N = 25;
func_times = zeros(N,5);
for n = 1:N
func_times(n,:) = timing_hist(2^n,500);
end
hold on
mark = 'xo*^dsp';
for k = 1:size(func_times,2)
plot(1:size(func_times,1),log10(func_times(:,k).*1000),['-' mark(k)],...
'MarkerEdgeColor','k','LineWidth',1.5);
end
hold off
xlabel('Log_2(Array size)','FontSize',16)
ylabel('Log_{10}(Execution time) (ms)','FontSize',16)
legend({'for','unique & for','tabulate','histcounts','accumarray','bsxfun','ndgrid'},...
'Location','NorthWest','FontSize',14)
grid on
1 这个奇怪的名称来源于我的领域,生态学。我的模型是元胞自动机,通常模拟虚拟空间中的个体生物(上面的M)。这些个体属于不同的物种(因此称为spp),共同组成所谓的“生态群落”。群落的“状态”由每个物种的个体数量组成,即本答案中的spp向量。在这些模型中,我们首先为个体定义一个物种库(上面的X),而群落状态考虑了物种库中的所有物种,而不仅仅是存在于M中的物种。
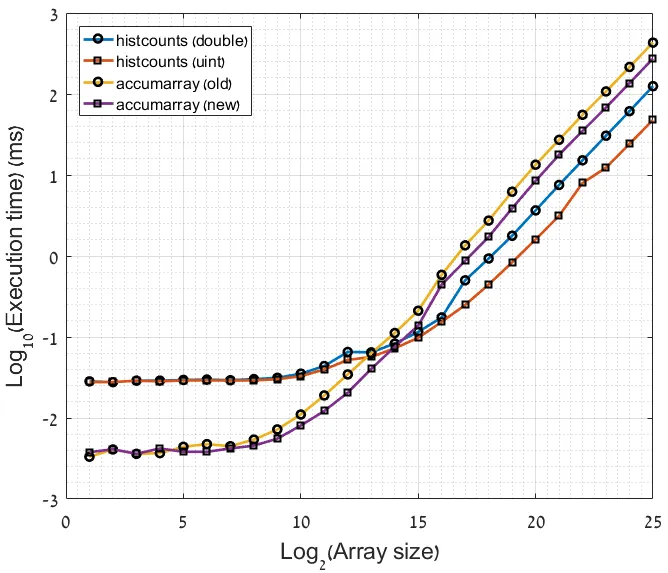
9是一个有效的数字,恰巧没有出现呢? - Dev-iL