让我们有以下数据
IF OBJECT_ID('dbo.LogTable', 'U') IS NOT NULL DROP TABLE dbo.LogTable
SELECT TOP 100000 DATEADD(day, ( ABS(CHECKSUM(NEWID())) % 65530 ), 0) datesent
INTO [LogTable]
FROM sys.sysobjects
CROSS JOIN sys.all_columns
我想计算行数,去年的行数和过去十年的行数。可以通过使用条件聚合查询或使用子查询来实现,如下所示:
-- conditional aggregation query
SELECT
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
-- subqueries
SELECT
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
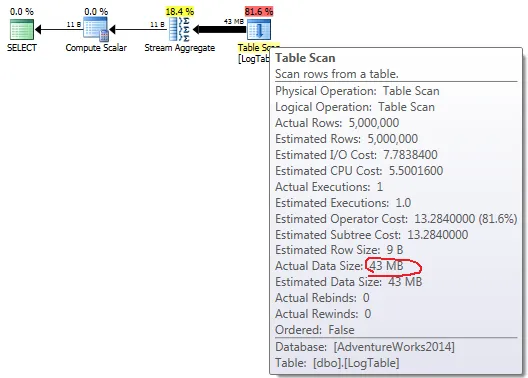
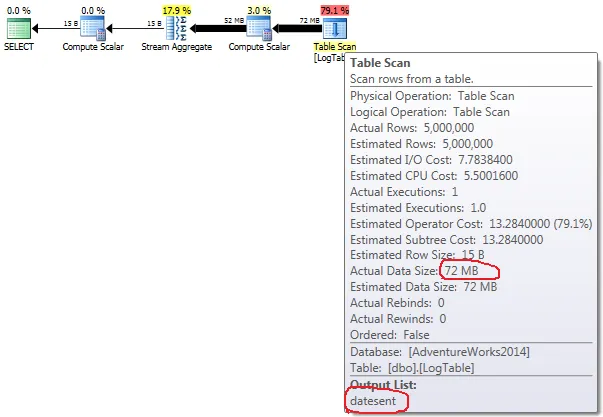
如果你执行查询并查看查询计划,你会看到像这样的内容:
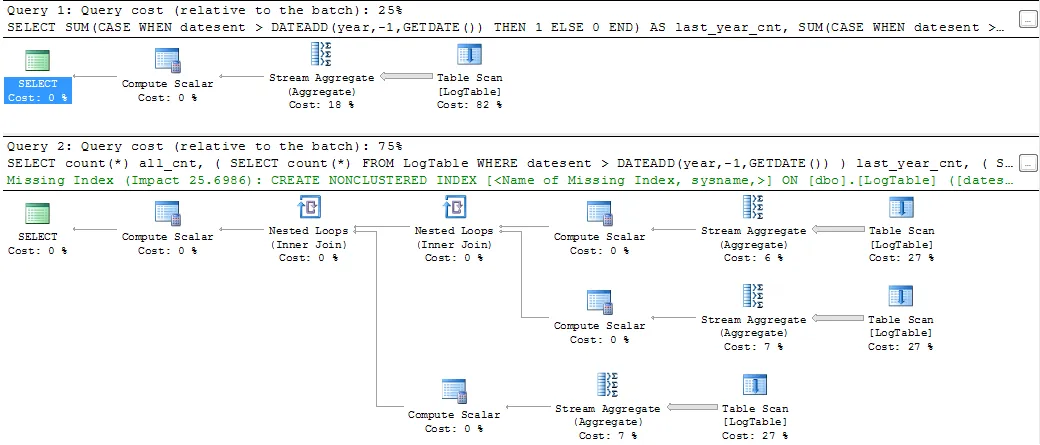
显然,第一个解决方案有更好的查询计划、成本估算,甚至SQL命令看起来更加简明和漂亮。但是,如果你使用 SET STATISTICS TIME ON 测量查询的CPU时间,我得到以下结果(我已经进行了几次测量,结果大致相同)。
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 41 ms.
(1 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 26 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
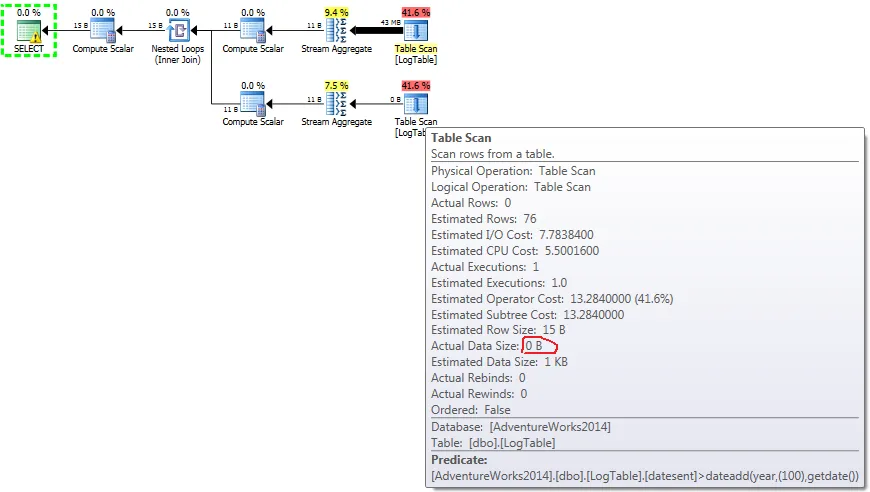
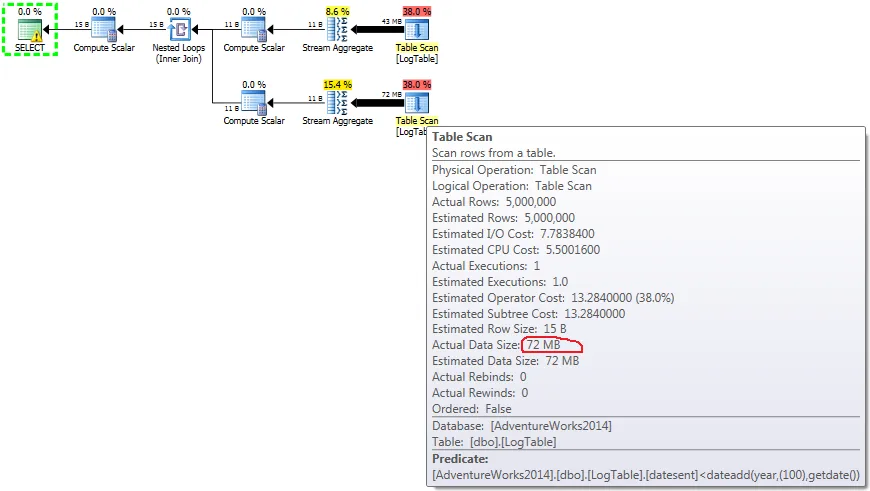
datesent 属性上创建索引,差异会变得更加明显。CREATE INDEX ix_logtable_datesent ON dbo.LogTable(DateSent)
那么第二种解决方案开始使用Index Seek而不是Table Scan,在我的电脑上,查询CPU时间性能下降到16ms。
我的问题有两个:(1)为什么条件聚合解决方案在没有索引的情况下不能至少优于子查询解决方案,(2)是否可以为条件聚合解决方案创建“索引”(或重写条件聚合查询),以避免扫描,或者如果我们关注性能,则条件聚合通常不适用?
附注:我可以说,这种情况对于条件聚合来说相当乐观,因为我们选择了始终导致使用扫描的所有行数。如果不需要所有行数,则具有子查询的索引解决方案没有扫描,而具有条件聚合的解决方案仍然必须执行扫描。
编辑
Vladimir Baranov基本上回答了第一个问题(非常感谢)。然而,第二个问题仍然存在。我可以在StackOverflow上看到使用条件聚合解决方案的答案非常频繁,它们吸引了很多注意力,被认为是最优雅和清晰的解决方案(有时被提议为最有效的解决方案)。因此,我将略微概括问题:
你能给我一个例子,条件聚合明显优于子查询解决方案吗?
为简单起见,假设不存在物理访问(数据在缓冲区高速缓存中),因为今天的数据库服务器仍然将大部分数据保留在内存中。

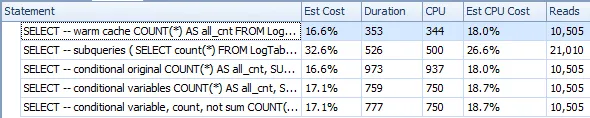
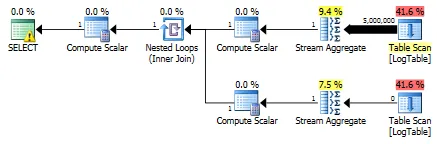

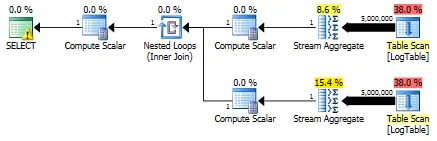
WHERE列上建立索引后,单独的子查询优于条件聚合。 - Tim Biegeleisen