我有一个大学毕业生数据库,并希望提取大约1000条数据的随机样本。
我希望确保样本代表人群,因此希望包括相同比例的课程,例如下图:
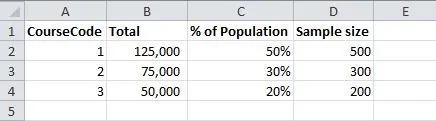
我可以使用以下方法实现这一点:
select top 500 id from degree where coursecode = 1 order by newid()
union
select top 300 id from degree where coursecode = 2 order by newid()
union
select top 200 id from degree where coursecode = 3 order by newid()
但我们有数百个课程代码,因此这将是耗时的。 我希望能够重用此代码以适用于不同的样本大小,并且不想通过查询和硬编码样本大小。
非常感谢任何帮助。