我有一个包含数千条记录的.txt文档。
其中一些记录看起来是这样的
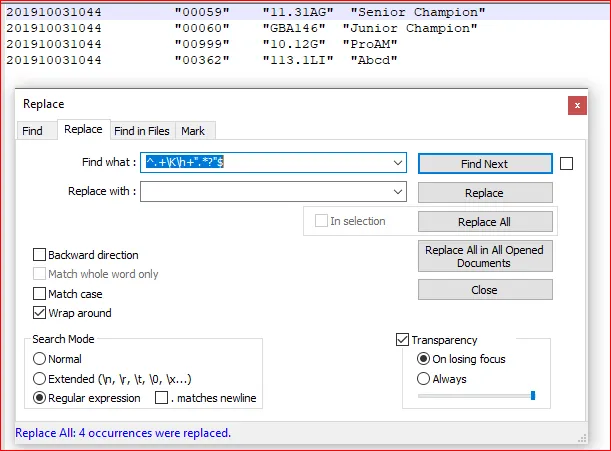
每当出现类似的记录时,我想删除最后引号中的最后一个单词/数字等(例如“高级冠军”,“初级冠军”等,这里有许多可能性)。
例如(之前):
我尝试了以下的正则表达式,但它不能工作。
搜索:
好的,我忘了点号(.)符号,但即使我没有点号(.)符号,它也无法工作。不确定使用多个加号(+)符号时是否有任何关系。
201910031044 "00059" "11.31AG" "Senior Champion"
201910031044 "00060" "GBA146" "Junior Champion"
201910031044 "00999" "10.12G" "ProAM"
201910031044 "00362" "113.1LI" "Abcd"
每当出现类似的记录时,我想删除最后引号中的最后一个单词/数字等(例如“高级冠军”,“初级冠军”等,这里有许多可能性)。
例如(之前):
201910031044 "00059" "11.31AG" "Senior Champion"
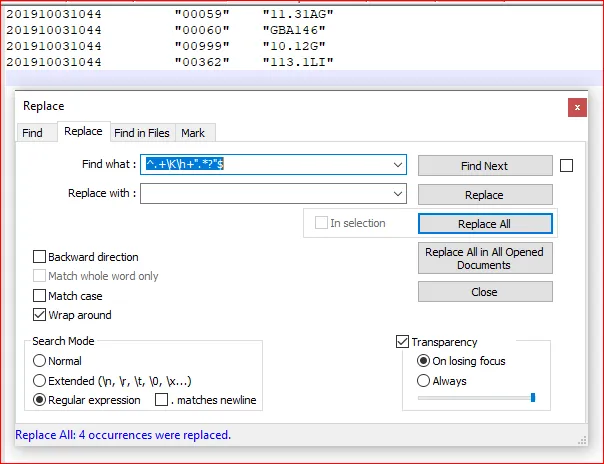
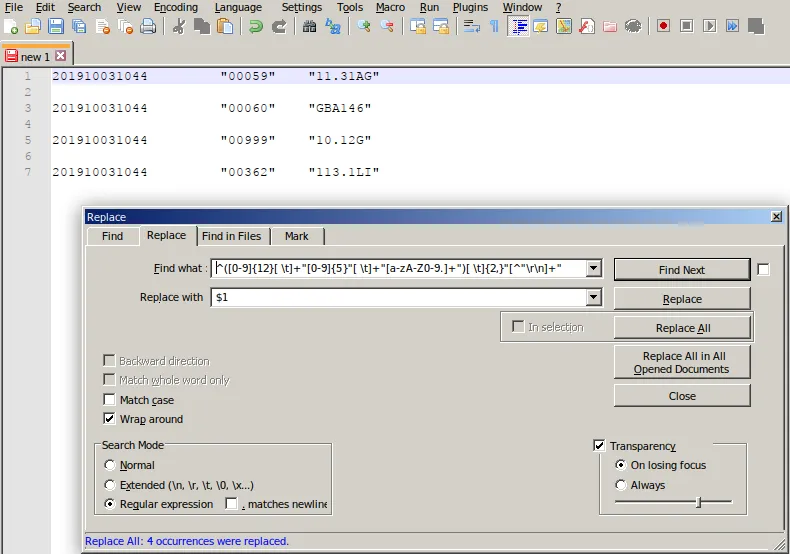
之后
201910031044 "00059" "11.31AG"
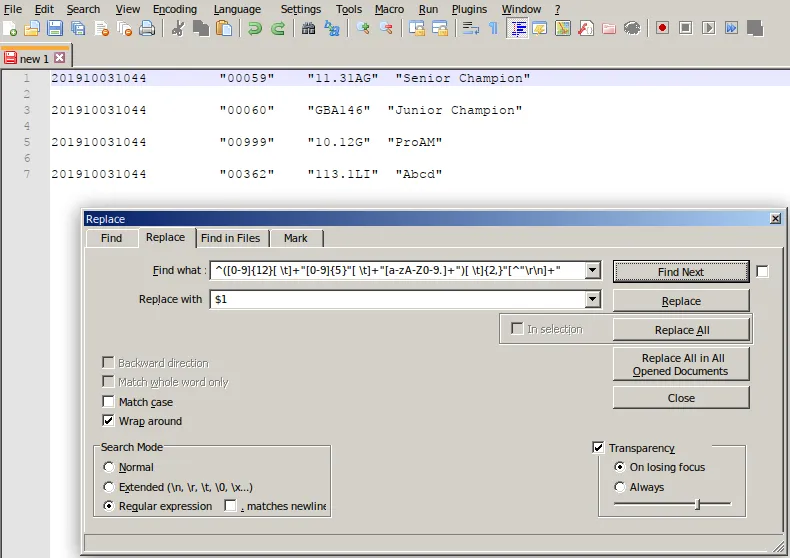
我尝试了以下的正则表达式,但它不能工作。
搜索:
^([0-9]{17,17} +“[0-9]{8,8}”+“[a-zA-Z0-9]”).*$
替换:\ 1(替换字符串)好的,我忘了点号(.)符号,但即使我没有点号(.)符号,它也无法工作。不确定使用多个加号(+)符号时是否有任何关系。