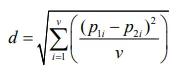假设有以下两个向量:
x = [(10-1).*rand(7,1) + 1; randi(10,1,1)];
y = [(10-1).*rand(7,1) + 1; randi(10,1,1)];
前七个元素是[1,10]范围内的连续值。最后一个元素是[1,10]范围内的整数。
现在我想计算x和y之间的欧几里得距离。我认为整数元素是一个问题,因为所有其他元素可能非常接近,但整数元素始终具有间隔为1的空间。因此,对整数元素有偏见。
我该如何计算类似于归一化欧几里得距离的东西?
假设有以下两个向量:
x = [(10-1).*rand(7,1) + 1; randi(10,1,1)];
y = [(10-1).*rand(7,1) + 1; randi(10,1,1)];
前七个元素是[1,10]范围内的连续值。最后一个元素是[1,10]范围内的整数。
现在我想计算x和y之间的欧几里得距离。我认为整数元素是一个问题,因为所有其他元素可能非常接近,但整数元素始终具有间隔为1的空间。因此,对整数元素有偏见。
我该如何计算类似于归一化欧几里得距离的东西?
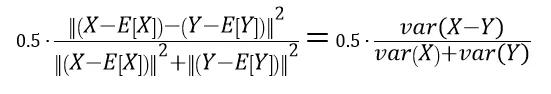
你可以使用MATLAB进行计算:
0.5*(std(x-y)^2) / (std(x)^2+std(y)^2)
或者,您可以使用:
0.5*((norm((x-mean(x))-(y-mean(y)))^2)/(norm(x-mean(x))^2+norm(y-mean(y))^2))
在计算距离之前,我更希望将x和y标准化,然后使用基本的欧几里得距离即可。
以您的示例为例
x_norm = (x -1) / 9; % normalised x
y_norm = (y -1) / 9; % normalised y
dist = norm(x_norm - y_norm); % Euclidean distance between normalised x, y
然而,我不确定是否拥有整数元素会导致某种偏见,但我们已经偏离了stackoverflow的主题 :)
SYSTAT,Primer 5和SPSS提供数据归一化选项,以便研究人员计算一个基本上是“无尺度”的距离系数。 Systat 10.2的归一化欧几里得距离通过将属性或个体之间的每个平方差异除以平方差异总数(或样本大小)来进行“归一化”。