假设我们有一个食品数据库,其中包括以下内容:
现在我们需要计算每个项目的得分并推荐最佳项目:
我已将问题建模为一个图: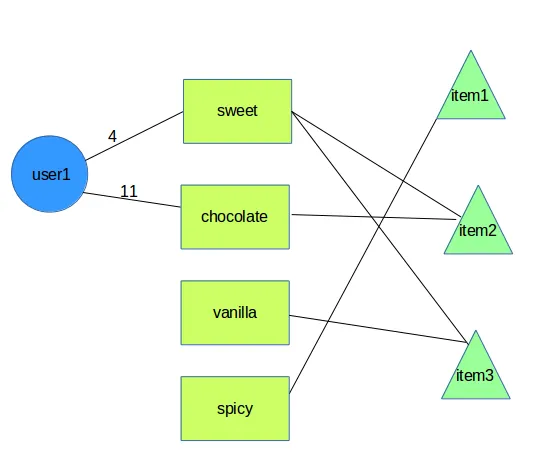 获取推荐的正确方式是什么——使用自定义遍历对象还是只使用AQL过滤和计数,或者在Foxx(JavaScript层)中实现它?
获取推荐的正确方式是什么——使用自定义遍历对象还是只使用AQL过滤和计数,或者在Foxx(JavaScript层)中实现它?
此外,您能否提供所建议方法的示例实现?
谢谢!
item1 = {name: 'item1', tags: ['mexican', 'spicy']};
item2 = {name: 'item2', tags: ['sweet', 'chocolate', 'nuts']};
item3 = {name: 'item3', tags: ['sweet', 'vanilla', 'cold']};
我们有一个用户正在寻找食物推荐,他们指出了他们对某些标签的偏好权重:
foodPref = {sweet: 4, chocolate: 11}
现在我们需要计算每个项目的得分并推荐最佳项目:
item1 score = 0 (doesn't contain any of the tags user is looking for)
item2 score = 4 (contains the tag 'sweet')
item3 score = 15 (contains the tag 'sweet' and 'chocolate')
我已将问题建模为一个图:
获取推荐的正确方式是什么——使用自定义遍历对象还是只使用AQL过滤和计数,或者在Foxx(JavaScript层)中实现它?此外,您能否提供所建议方法的示例实现?
谢谢!