我正在尝试学习如何制作编译器。为此,我阅读了很多关于上下文无关语言的资料。但是有一些问题我自己还无法理解。
由于这是我的第一个编译器,我不知道一些惯例。我提出的问题是为了构建一个解析器生成器,而不是编译器或词法分析器。有些问题可能很明显。
我阅读过的内容包括:自底向上解析、自顶向下解析、形式化语法。图像来自于:杂项解析。所有资料均来自斯坦福大学CS143班级。
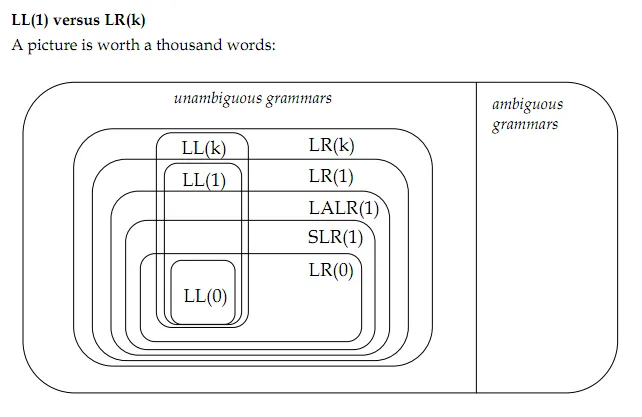
以下是要点:
0)模棱两可的和左递归/右递归的方式如何影响算法选择?是否还有其他描述语法的方式?
1)多义语法是指具有多个解析树的语法。但是选择最左派导或最右派导是否应该导致解析树的唯一性?
[编辑:在这里回答了]。
2.1)但是,语法的歧义是否与k有关?我的意思是,给出一个LR(2)语法,对于LR(1)解析器来说,它是否是不明确的而对于LR(2)解析器来说不是?
[编辑:不是,LR(2)语法意味着解析器需要向前看两个标记才能选择正确的规则。另一方面,多义语法是指可能导致多个解析树的语法。]
2.2)那么,只要您可以想象到它,LR(*)解析器就没有任何歧义的语法,因此可以解析整个上下文无关语言集吗?
[编辑:由Ira Baxter回答,LR(*)比GLR弱,因为它不能处理多个解析树。]
3)根据前面的答案,下面的问题可能是自相矛盾的。考虑LR解析,模棱两可的语法是否会触发移位-归约冲突?一个不明确的语法是否也会触发这种冲突?同样,减少-减少冲突呢?
[编辑:这是它,模糊语法会导致移进规约和规约规约冲突。反证法表明,如果没有冲突,则语法是唯一的。]
4)相比LL(k),LR(k)解析器具有解析左递归语法的能力,这是它们之间的唯一区别吗?
[编辑:是的。]
5)给出G1:
G1 :
S -> S + S
S -> S - S
S -> a
5.1) G1语法同时具有左递归、右递归和二义性,对吗?它是LR(2)文法吗?我们可以使它无歧义:
G2 :
S -> S + a
S -> S - a
S -> a
5.2) G2是否仍然含糊不清?G2的解析器是否需要两个lookahead?通过因式分解,我们有:
G3 :
S -> S V
V -> + a
V -> - a
S -> a
5.3) 现在,G3的解析器是否只需要一个前瞻?进行这些转换的对应部分是什么?LR(1)是所需的最小解析器吗?
5.4) G1具有左递归性质,为了使用LL解析器解析它,需要将其转化为右递归语法:
G4 :
S -> a + S
S -> a - S
S -> a
那么。
G5 :
S -> a V
V -> - V
V -> + V
V -> a
5.5) G4需要至少LL(2)分析器吗?仅G5可由LL(1)分析器分析,G1-G5定义了相同的语言,该语言为(a(+/- a)^n)。是真的吗?
5.6) 对于每个文法G1到G5,它所属的最小集合是什么?
6) 最后,由于许多不同的文法可以定义相同的语言,如何选择文法和相关的解析器?结果产生的解析树重要吗?解析树的影响是什么?
我提出了很多问题,并不指望完整的答案,但任何帮助都将非常感激。
感谢阅读!